
Programas tradicionais geralmente executam em uma única linha sequencial de execução (single thread). Dividir o processo a ser executado em múltiplas threads com tarefas que podem ser executadas de forma concorrente traz um ganho significativo ao desempenho do algoritmo, principalmente com a popularização de processadores multi-núcleo, onde as threads são executadas realmente de forma simultânea. Neste post vou mostrar como paralelizar o web crawler em ruby que implementei anteriormente.
Em Ruby, em sua biblioteca padrão, as threads que o programa em execução lança só conseguem tirar proveito do desempenho de um núcleo do processador, devido ao Global Interpreter Lock (GIL), que assegura que somente um código Ruby seja executado ao mesmo tempo. Ainda assim, é possível tirar proveito do seu desempenho em situações onde seu algoritmo faz múltiplas chamadas de entrada/saída (como requisições HTTP à uma API externa, por exemplo), nas quais o programa em execução fica bloqueado aguardando a resposta para então seguir com a próxima requisição. Com múltiplas threads, ao aguardar uma resposta, a thread em execução pode dar lugar a uma outra que vai disparar uma nova requisição, otimizando o tempo de execução real.
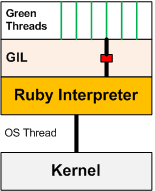
Fluxo de execução com Global Interpreter Lock
Ao utilizar esse paradigma de programação, entretanto, é necessário ter em mente a forma concorrente em que seu algoritmo vai ser processado. Isso implica que você não tem garantia da ordem de execução de suas threads, o que pode causar condições de corrida, onde o algoritmo gera uma saída inesperada dependendo da ordem de execução. No caso do web crawler implementado, cada requisição feita para recuperar um post individual pode ser executada de forma independente sem prejuízo de resultado. Essa tarefa de buscar uma postagem individual é o trecho de código que vai ser disparado para diferentes threads executarem.
O CÓDIGO-FONTE
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
#! /usr/bin/env ruby require 'nokogiri' require 'open-uri' require 'thread' require 'thwait' categorias_urls = [ "http://www.acasadocogumelo.com/search/label/Mario", "http://www.acasadocogumelo.com/search/label/Pok%C3%A9mon", "http://www.acasadocogumelo.com/search/label/Donkey%20Kong", "http://www.acasadocogumelo.com/search/label/Zelda" ] threads_posts = [] posts = [] categorias_urls.each do |url| # Fetch and parse HTML document doc = Nokogiri::HTML(open(url)) #Pegando a lista de posts disponíveis na categoria posts_summary = doc.css(".post-summary").search("strong").search("a").map{|a| [a.attributes["title"].value, a.attributes["href"].value]} #Extraindo as informações de cada post posts_summary.each do |post| threads_posts << Thread.new{ titulo_post = post[0] link_post = post[1] post = Nokogiri::HTML(open(link_post)) post_body = post.css(".post-body.entry-content").first.inner_html posts << {titulo: titulo_post, link: link_post, conteudo: post_body, categoria: url} } end #Aguardando todas a threads executarem para prosseguir ThreadsWait.all_waits(*threads_posts) end puts posts |
Em relação ao código original, poucas modificações. No cabeçalho, são requisitadas as bibliotecas thread e thwait (que permite delimitar um ponto onde é esperado todas as threads finalizarem a sua execução). Todas as threads criadas com o código do bloco Thread.new são adicionadas a um array que será o argumento da função de espera. No caso em questão, adicionei as postagens mineradas a um array para demonstrar que em alguns casos é interessante aguardar a finalização da execução de todas as threads, a fim de garantir que o array estará completamente populado quando for utilizado posteriormente. Em um caso de aplicação onde cada postagem seria persistida individualmente em um banco de dados, por exemplo, essa espera não seria necessária.
É possível, ainda nesse código, paralelizar também as requisições às páginas de categoria, que possuem a mesma característica. À medida que essa lista cresce, cresce também o ganho em termos de tempo de execução. Em testes empíricos, a execução de algoritmos com essas características chega a ser cerca de 10 vezes mais rápida quando as requisições são feitas de forma concorrente. Existem outras gems e possibilidades menos triviais de fazer esse tipo de implementação, que podem ser mais eficientes dependendo do contexto da sua aplicação. Quaisquer dúvidas ou sugestões, utilize o campo de comentários ou entre em contato!
1 Comentário
Sannytet
12 de dezembro de 2018 at 01:46Nice posts! 🙂
___
Sanny