
Nota: este artigo foi desenvolvido em parceria com Thiago Silveira (thiagosousasilveira@gmail.com) pela disciplina de Algoritmos e Estrutura de Dados III, do curso de Ciência da Computação pela Universidade Federal de São João del-Rei (UFSJ), sob a orientação do Professor Leonardo Rocha (lcrocha@ufsj.edu.br). O código-fonte da implementação pode ser obtido aqui.
1- INTRODUÇÃO
Dentre as diferentes classes de algoritmos conhecidas, a de geometria computacional se destaca por sua aplicabilidade em diversas áreas, especialmente na computação gráfica. Um problema particular de geometria computacional será apresentado neste trabalho: o convex hull, ou fecho convexo no plano.
O fecho convexo de um número de pontos no plano pode ser visualizado intuitivamente a partir de uma tira elástica que ao ser esticada envolva todo o objeto dado, e quando ela é solta, ela assumirá a forma requerida do fecho. Neste trabalho serão estudados 5 algoritmos em particular que encontram os pontos do convex hull: gift wrapping algorithm, graham scan, quickhull, Monotone Chain e incremental algorithm, dos quais dois serão escolhidos para serem paralelizados.
Em alguns casos, onde há a necessidade de alto desempenho de processamento, a manipulação de dados é feita de forma concorrente pelos processos e, com computadores paralelos, os ganhos em termos de tempo são consideráveis. O processamento paralelo dos algoritmos citados será abordado ao longo do trabalho.
2 – CONVEX HULL
O problema do convex hull se encaixa na área da geometria computacional. Dado um conjunto de pontos em um espaço, o problema consiste em encontrar o menor número de pontos que gerem um polígono convexo no qual abranja todos os outros pontos. A imagem abaixo é um exemplo do convex hull. Dos vários pontos, somente os pontos mais externos e que formam o menor polígono que “fechem” todos os outros pontos.
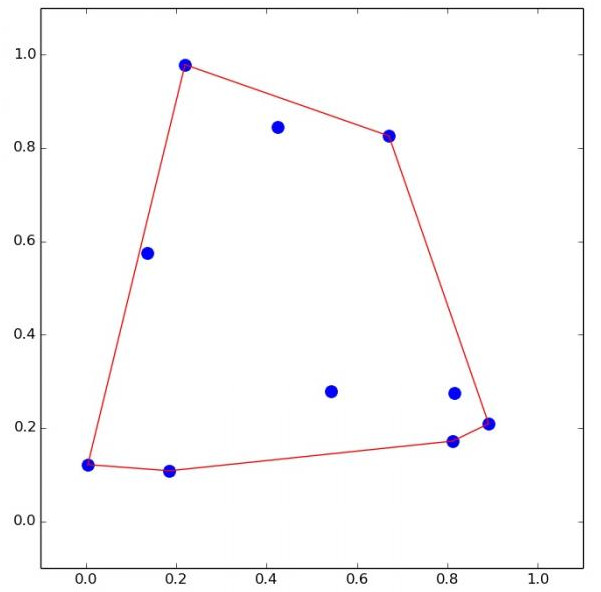
Exemplo de caso e solução do Convex Hull
O convex hull pode ser expandido para 3 ou mais dimensões. Portanto, não se limita ao plano. Além disso, ele pode ser aplicado em diversos problemas: ray tracing, videogames, busca de caminhos em robótica, sistemas de informação geográfica, entre vários outros.
3 – OS ALGORITMOS
O objetivo do trabalho é paralelizar dois algoritmos de construção do convex hull. Para isso, foram analisados 5 algoritmos já conhecidos quanto as suas oportunidades de serem paralelizados.
Para implementação concorrente dos algoritmos citados, foi utilizada a biblioteca pthreads da linguagem C. A entrada do programa é lida de um arquivo de texto e considera o caso geral, onde os pontos são dados de forma não-ordenada.
A entrada é composta por vários casos de teste. A primeira linha de um caso de teste contém um inteiro N, que indica o número de pontos contidos no caso de teste, as N linhas seguintes contém um par de inteiros x, y, que indicam as coordenadas do i-ésimo ponto. O final da entrada é indicado quando N = 0.
A saída do programa é escrita no arquivo de saída tp4.out. Para cada conjunto de teste da
entrada, o programa informa o resultado do fecho do “Teste k”, onde k é numerado a partir de 1. A lista de pontos pertencentes ao fecho é listada em sentido anti-horário.
3.1 – GRAHAM SCAN
O primeiro passo do algoritmo Graham Scan é encontrar o ponto com menor coordenada y. Chamamos esse ponto de P. Se há mais de um ponto com a menor coordenada, o ponto com menor coordenada x dentre estes é escolhido.
No próximo passo, cada ponto Q do conjunto de pontos deve ser ordenado em ordem crescente de acordo com o ângulo que a reta PQ faz com o eixo x. O algoritmo procede considerando cada um dos pontos no vetor ordenado.
Para cada ponto, a virada é determinada se movendo dos dois pontos anteriores ao ponto considerado. Esta pode ser à esquerda ou a direita. Se for à direita, isso significa que o penúltimo ponto destes não faz parte do fecho convexo e deve ser desconsiderado. Esse processo é repetido enquanto o conjunto de três pontos fizer essa “virada à direita”. Assim que uma “virada à esquerda” é encontrada, o algoritmo considera o próximo ponto do vetor ordenado. (Se em qualquer passo os três pontos forem colineares, deve-se optar por incluí-lo ou descartá-lo, uma vez que algumas aplicações se faz necessário encontrar todos os pontos da borda do convex hull).
Para determinar se três pontos constituem uma “virada à esquerda” ou uma “virada à direita”, pode se fazer um cálculo aritmético simples chamado produto cruzado. Para três pontos (x1,y1),(x2,y2) e (x3,y3), simplesmente calcula-se a direção do produto cruzado de dois vetores conectando o ponto (x1,y1) ao (x2,y2) e o ponto (x1,y1) ao (x3,y3), que é dado pela expressão: (x2 – x1)(y2 – y3) – (y2 – y1)(x3 – x1). Se o resultado é 0, os três pontos são colineares; se é positivo, os três pontos fazem uma “virada à esquerda” ou sentido anti-horário; caso contrário, uma “virada à direita” ou sentido horário.
Esse processo finalmente retornará ao ponto de início, que é quando o conjunto de pontos do convex hull está completo no sentido anti-horário, chegando-se ao objetivo principal. Neste algoritmo pode-se ver várias oportunidades de paralelismo. O cálculo do ponto P pode ser dividido para vários processos, bem como o cálculo dos ângulos que os pontos fazem com o ponto P. Além disso, a ordenação, que é um processo custoso, também pode ser paralelizado. Já o código que descobre os pontos no hull não tem uma paralelização trivial, pois para se descobre um ponto, dependemos dos pontos anteriormente descobertos, a não ser pelo primeiro(Ponto P) que sabemos que está no hull.
3.2 – MONOTONE CHAIN
O Monotone Chain inicia com uma fase de pré-processamento que se trata de fazer uma ordenação crescente do conjunto de pontos dados de acordo com a coordenada x (em caso de empate, a coordenada y é consultada). A seguir, serão obtidos os vértices da parte de baixo e de cima do fecho.
Para a parte de baixo do fecho, enquanto o conjunto L de pontos (que são os pontos que compõe a parte debaixo do fecho) conter pelo menos dois pontos, o vetor ordenado é percorrido e enquanto a sequência dos dois últimos pontos de L e P[i] não fizer uma “virada” no sentido anti-horário, remove-se o último ponto de L, e adiciona-se P[i] em L. O mesmo processo é realizado para os pontos do conjunto U do fecho superior. Para ambos os casos, todos os pontos são percorridos, pois não sabemos qual é o ponto que delimita o fim da parte de baixo do fecho, uma vez que é a partir deste que a parte de cima começa.
O algoritmo de ordenação, assim como no Graham Scan, é uma oportunidade de paralelização. Já o código do cálculo do fecho pode ser dividido para 2 threads(parte de cima e parte de baixo), porém não é uma tarefa simples uma vez que para começar a análise superior, é necessário primeiro descobrir o ponto final da análise inferior.
3.3 – QUICK HULL
O algoritmo tem seu princípio de funcionamento similar ao algoritmo de ordenação quicksort, de onde deriva-se seu nome. Tal princípio de funcionamento consiste em encontrar os pontos mais à esquerda e direita, e, dada a reta traçada por esses dois pontos, fazer a divisão do conjunto de pontos em outros dois conjuntos S1 e S2.
Esses conjuntos de pontos são processados recursivamente, da seguinte forma: o ponto mais distante da linha que divide o conjunto de pontos dado, faz parte do fecho convexo, e forma juntamente com os pontos da reta, um triângulo. Os pontos contidos neste triângulo já estão claramente inseridos no polígono e podem ser descartados de futuras análises. Este processo é repetido de forma recursiva para as duas linhas formadoras do triângulo (excluindo-se a linha inicial), de forma que o procedimento retorna quando o conjunto de pontos a se analisar é vazio, e o conjunto de pontos do fecho convexo está formado.
No caso do Quick Hull, as oportunidades de paralelismo se encontram primeiramente na fase de pré-processamento, onde a tarefa de percorrer o vetor e encontrar o ponto com maior e menor valor de x pode ser dividida para p processos. Após o pré-processamento, como a reta divide o conjunto de pontos em duas regiões, o mesmo número de processos poderia executar as devidas ações de forma concorrente. Entretanto o objetivo do trabalho é fazer o paralelismo para um número genérico p de processadores, sendo então esta última estratégia inválida.
3.4 – GIFT WRAPPING ALGORITHM
O algoritmo gift wrapping faz sua inicialização com a variável i=0 e um ponto p0 conhecido do convex hull (ponto mais à esquerda). Posteriormente, seleciona o ponto p i+1 de forma que todos os pontos estejam à direita da linha traçada pelos pontos p i p i+1. Tal ponto pode ser obtido através de uma varredura nos demais pontos, a fim de se obter o ponto i+1, de forma que, a reta p i p i+1 faça o maior ângulo possível com o eixo x.
Incrementando a variável i, e repetindo os passos anteriores até que ph=p0, obtém-se o conjunto de pontos do convex hull. Para o problema dado em duas dimensões, o algoritmo gift wrapping é similar ao enrolamento de uma corda ao redor do conjunto de pontos.
Quanto à oportunidade de paralelismo, na fase de pré-processamento, onde se obtém o ponto mais à esquerda, a tarefa de varrer o vetor pode ser dividida para p processadores. Outra oportunidade é no passo de se encontrar o ponto i+1 que faz parte do fecho, onde a varredura no vetor de pontos e seus respectivos cálculos de ângulo podem ser divididos para a mesma quantidade p de processadores.
3.5 – ALGORITMO INCREMENTAL
O algoritmo incremental do convex hull é relativamente simples de se implementar, e possui a possibilidade de se generalizar para maiores dimensões. O algoritmo opera inserindo pontos um a um e progressivamente atualiza o fecho. Se o novo ponto está dentro do fecho, não há nada a fazer.
Caso contrário, deve-se deletar todas as arestas que o novo ponto alcança. Então faz-se a conexão entre o novo ponto e os dois pontos vizinhos e atualiza-se o fecho. Repetindo este processo para os pontos restantes fora do fecho, finalmente obtém-se o fecho convexo dos pontos dados.
A princípio, o algoritmo incremental não apresenta opções promissoras de paralelismo. O que inviabiliza a paralelização do algoritmo é a dependência entre os resultados, de forma que não é possível manipular os dados de forma concorrente. Logo, é um algoritmo de paralelismo inviável .
4 – IMPLEMENTAÇÃO
Dentre os 5 algoritmos analisados, os 4 primeiros foram implementados sequencialmente com objetivo de identificar melhor as partes a serem paralelizadas. Usando uma técnica de Profiling, onde calculamos o tempo gasto em cada uma das funções, foi visto quais algoritmos dependem mais de certas partes dos processos. O cálculo é mostrado abaixo.
Observando a análise dos tempos podemos perceber que o Graham Scan gasta a grande maioria do tempo no algoritmo de ordenação. Logo, é importante paralelizá-lo. O mesmo acontece para o algoritmo do Monotone Chain onde 80% do tempo é gasto no mergesort.
Para o quick hull, temos que a função de encontrar o hull é a que gasta 98% do tempo e é justamente a função que só podemos paralelizar para 2 threads. Logo, o descartarmos pois implementá-lo para um número genérico de processos não é trivial.
Já o gift wrapping, o cálculo do ângulo consome 87% do tempo e esta função tem custo constante, mas é requerida muitas vezes na hora de percorrer todos os pontos para escolher o próximo ponto do hull. Paralelizar essa busca pode ser uma alternativa, porém disparar threads e fechá-las cada vez que for preciso buscar será muito custoso para o algoritmo. Logo descartamos o gift wrapping. Então, os algoritmos escolhidos são Monotone Chain e Graham Scan.
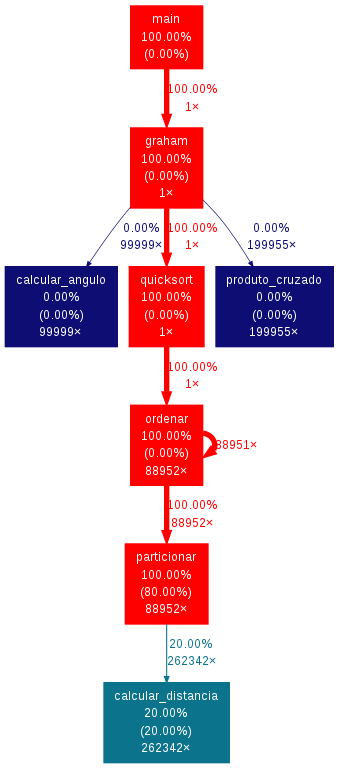
Profiling Graham Scan
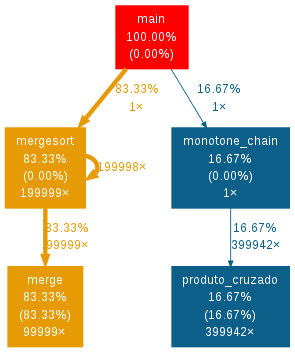
Profiling Monotone Chain
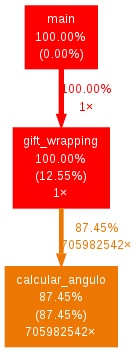
Profiling Gift Wrapping
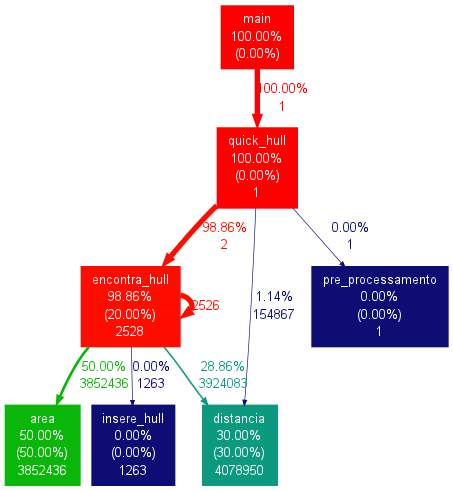
Profiling Quick Hull
4.1 – MONOTONE CHAIN
Como dito acima, o Monotone Chain gasta a maior parte do seu tempo na ordenação e esta foi a parte do código a ser paralelizada. Sequencialmente foi usado o mergesort, porém ele é recursivo. Percebe-se desta forma que sua paralelização não é simples. Outros algoritmos eficientes como o Quicksort(mesmo a versão iterativa) também não tem uma paralelização trivial.
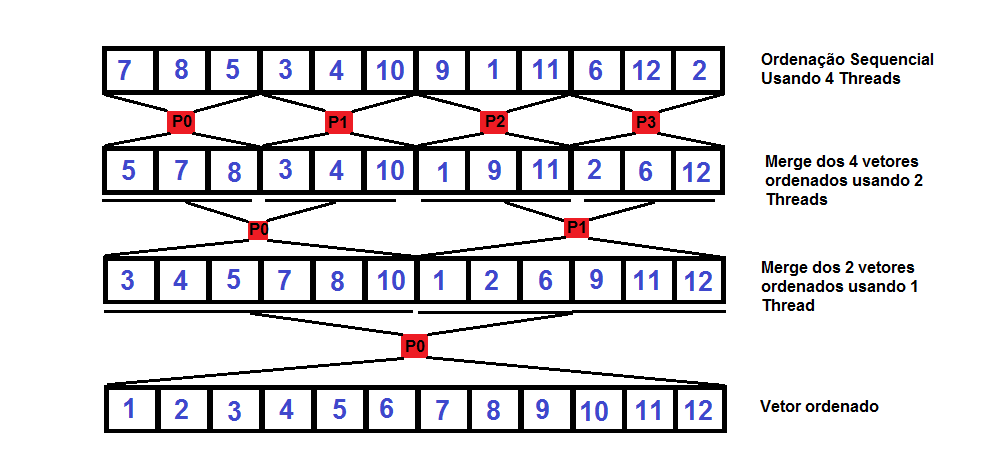
Optamos então por fazer uma técnica que junta vários algoritmos. Primeiramente dividimos o vetor a ser ordenado em p vetores. Cada um é lançado para uma das p threads para ser ordenado com algum algoritmo de ordenação sequencial, por exemplo, o Quicksort. Assim, temos p vetores ordenados.
Precisamos agora juntar os vetores. Para isso, usamos a técnica do merge do algoritmo mergesort. Dividimos o número de threads por 2 e juntamos dois a dois cada vetor ordenado em paralelo. O número de processos é sempre dividido por 2 até chegar em 1 thread que fará o merge final.
Temos duas exceções nestes casos. A primeira é que o número de vetores a ordenar pode não ser par. Caso isso aconteça, a última thread fará um merge triplo(juntando 3 vetores em 1). Desta forma evitamos que um processo fique ocioso. O outro problema é quando o tamanho de elementos não é divisível pelo número de processos. Para resolver isso, sempre jogamos os valores que sobram para que a última thread execute o merge neles. Fazendo assim, evitamos cálculos com os tamanho dos vetores e só nos preocupamos em calcular o tamanho do último.
O esquema abaixo exemplifica o funcionamento da ordenação paralela:
4.2 – GRAHAM SCAN
No Graham Scan várias partes foram paralelizadas. A primeira foi a busca pelo ponto de menor valor de y. Para buscar este ponto, dividimos o vetor de pontos em p processos e cada processo procura o menor ponto no seu vetor e atualiza numa variável global chamada “min”. Para evitar o acesso concorrente à variável, controlamos a escrita com um mutex.
Com o ponto P encontrado, calculamos os ângulos que os pontos fazem com P. Neste caso, disparamos p threads para calcular o ângulo dos pontos com o ponto P. Cada thread vai realizar os cálculos em uma parte do vetor de pontos(dividimos o vetor de pontos em p vetores). Assim, não precisamos de nos preocupar com o acesso concorrente, pois cada thread vai trabalhar partes diferentes do vetor. A ordenação pelo ângulo também foi paralelizada e tem a ideia idêntica à do Monotone Chain, porém agora não é ordenado pela coordenada x do ponto e sim pelo ângulo que faz com P.
5 – ANÁLISE DE COMPLEXIDADE
Nesta seção será apresentada uma análise da complexidade dos algoritmos de obtenção do fecho convexo e também um estudo sobre os piores e melhores casos de cada algoritmo.
5.1 – MONOTONE CHAIN
O algoritmo sequencial do Monotone Chain também tem complexidade O(n*logn). Suas partes são formadas pela ordenação(O(n*logn)) e busca em baixo(O(n)) e busca em cima(O(n)). Logo, O(n*logn)+2*(O(n))=O(n*logn), onde n é o tamanho do vetor. Já o algoritmo paralelo depende da complexidade da ordenação. Na ordenação temos que dividir o vetor pela quantidade p de threads e ordenar cada uma sequencialmente. Assim, a complexidade é dada por: O((n/p)*log(n/p)).
Além disso, temos o merge que une os vetores ordenados. Sua complexidade precisa ser calculada a partir de uma equação de recorrência. Apesar da função não ser recursiva, o número de threads é sempre dividido pela metade e trabalha com quantidades diferentes do vetor. Logo, a equação de recorrência é: T(p)=n/p +T(p/2), T(1)=O(n). Resolvendo-a temos que a complexidade é dada por O(n)+p*n*log(p)+(n/p)*log(n/p).
O Monotone Chain tem mais 2 pesquisas O(n)(calculo do hull inferior e superior). Então, somando as complexidades temos que será dada: 3*O(n)+p*n*log(p)+(n/p)*log(n/p) = O(n)+p*n*log(p)+(n/p)*log(n/p). Ou seja, mesmo paralelizado ainda depende da ordenação.
5.2 – GRAHAM SCAN
Sabemos que o algoritmo sequencial do Graham Scan tem complexidade O(n*logn). Suas partes são formadas por: busca do ponto de menor coordenada em y(O(n)), cálculo dos ângulos dos pontos(O(n)), ordenação(O(n*logn)), gerar o hull(O(n)). Logo, O(n*logn)+3*(O(n)) = O(n*logn).
A busca pelo ponto P é uma pesquisa em p vetores de tamanho n/p, logo a complexidade de tal busca é O(n/p). O mesmo acontece para o cálculo dos ângulos, a complexidade é O(n/p).
A complexidade da ordenação é a mesma da complexidade da ordenação do Monotone Chain, que é O(n)+p*n*log(p)+(n/p)*log(n/p).
Além disso, o algoritmo de graham ainda calcula o hull sequencialmente passando por todos os pontos. Isto é uma pesquisa O(n).
Então a complexidade total será dada por: 2*O(n/p)2*O(n)+p*n*log(p)+(n/p)*log(n/p) = O(n/p)+O(n)+p*n*log(p)+(n/p)*log(n/p).
6 – CONCLUSÃO
Neste trabalho, foram apresentados o estudo e análise dos 5 algoritmos de cálculo do convex hull, sendo deles: graham scan, Monotone Chain, quickhull, gift wrapping e incremental algorithm quanto à sua implementação e viabilidade de paralelização. Além disso, os algoritmos Monotone Chain e Graham Scan foram implementados paralelamente.
Devido às limitações físicas que impedem o aumento da frequência de processamento, essa alternativa de se realizar cálculos concorrentes em diferentes processos mostrou-se de grande importância e eficiência nos computadores atuais, sobretudo quando há necessidade de alto desempenho. Contudo, a implementação de algoritmos paralelizados mostrou-se demasiadamente complexa em relação ao algoritmo serial. Acima de tudo, depurar erros nessa nova forma de computar conjuntos de dados foi uma tarefa árdua e confusa, e pode apresentar muitos empecilhos.
Por fim, pode-se concluir que o trabalho foi de extrema importância para a aquisição de conhecimento referente ao tema. Essa importância pode ser justificada pela crescente demanda de tal habilidade, uma vez que, nos dias atuais, é a forma mais sofisticada de se fazer computação de alto desempenho.
1 Comentário
Sannytet
11 de dezembro de 2018 at 16:00Nice posts! 🙂
___
Sanny