
Nota: Este artigo foi desenvolvido para a disciplina de TICs (Tecnologias de Informação e Comunicação) aplicadas à saúde pelo curso superior de Bacharelado em Ciência da Computação da UFSJ, sob orientação do professor Dárlinton Carvalho (darlinton@gmail.com).
1 – INTRODUÇÃO
Com o crescimento da adesão dos internautas às redes sociais, o volume de dados gerados pela interação dos usuários com essas plataformas tem crescido exponencialmente (Big Data). Juntamente com o crescimento desse volume de dados, cresce também o interesse por parte de pesquisadores na descoberta de conhecimentos implícitos acerca desses dados. Esse interesse impulsiona o desenvolvimento de técnicas de mineração de dados e aprendizado de máquina, cujas utilizações auxiliam nesse processo de descoberta de conhecimento.
O objetivo deste trabalho é desenvolver uma aplicação que sirva como um repositório de informações relevantes em dados coletados sobre doenças. A fonte de coleta desses dados são as principais redes sociais e o conjunto de doenças apresentado será definido de acordo com a relevância e taxa de postagem, buscando uma quantidade significativa de dados. A aplicação web visa fornecer visualizações e descoberta de conhecimentos não triviais acerca desses dados, como distribuição geográfica dos usuários apresentadas em um mapa, termos mais frequentes, gráficos de uso de sistemas operacionais, dentre outras visualizações mais intuitivas. Essa intuitividade visa tornar esse repositório fonte de informações tanto para pesquisadores e especialistas quanto para usuários mais leigos.
2 – REFERENCIAL TEÓRICO
2.1 – COLETORES DE DADOS EM REDES SOCIAIS
Uma vez que a fonte de dados da aplicação desenvolvida provém das postagens dos usuários em redes sociais, faz-se necessário também o desenvolvimento de métodos para coleta desses dados. As redes sociais que serão fontes de coleta (Facebook, Instagram e Twitter) possuem suas próprias API’s (Application Programming Interfaces), que auxiliam os desenvolvedores na elaboração de aplicações relacionadas a essas plataformas. Logo, faz-se necessário o desenvolvimento de um coletor voltado para cada uma dessas redes através das interfaces disponibilizadas.
2.1.1 – FACEBOOK
Para a coleta de dados do Facebook, foi utilizada a Graph API. Atualmente em sua segunda versão (v2.2), a Graph API é baseada em HTTP, e portanto, pode ser utilizada através de qualquer linguagem que suporte esse tipo de requisição. Através dessas requisições, é possível recuperar informações a respeito dos usuários, da estrutura do grafo da rede social (ligações entre usuários) e também sobre as postagens (desde que esses dados sejam públicos). A pesquisa em postagens, utilizadas pela aplicação aqui desenvolvida, é oferecida pela versão 1.0 da API, que será mantida ativa somente até a data de 30 de Abril de 2015, não sendo possível (em primeira instância) fazer pesquisas futuras nas postagens da rede. Para a pesquisa de postagens, a URL de requisição tem o seguinte formato:
|
1 |
https://graph.facebook.com/search?s=query&type=’post’&access_token=TOKEN |
Os parâmetros da requisição consistem do termo a ser buscado (query), do alvo das buscas (postagens, type=’post’) e do token de acesso da aplicação, que deve ser previamente cadastrada na plataforma de desenvolvimento do facebook, fornecendo à aplicação a chave de acesso. Entretanto, uma vez que a versão 1.0 da API não será mantida, as aplicações registradas posteriormente já fazem as requisições à última versão, que não possui o método de busca.
A resposta da requisição feita é um objeto JSON (JavaScript Object Notation), que é um modelo para armazenamento e transmissão de informações no formato texto, amplamente utilizado para troca de informações na web. As informações retornadas no caso em questão são um conjunto de postagens e metadados, como informações do autor da postagem (bem como informações sobre este), número de curtidas, localização (se disponível), dentre outros. Além disso, esse mesmo modelo JSON contém um atributo que
indica uma URL com a próxima página dos resultados da pesquisa realizada.
Para coletar as informações da rede, o processo consiste então basicamente em fazer a requisição, processar as informações recuperadas (comumente armazená-las para posterior utilização) e, por fim, fazer uma nova requisição, de acordo com o novo link de página obtido. É importante levar em consideração também que essas API’s possuem um limite de requisições por período de tempo. Para o caso da Graph API, o código de retorno 17 com a mensagem “Error, Code: 17, Message: User request limit reached” indica o excedimento. É possível ainda que o objeto JSON retornado não contenha um link de próxima página, por ausência de mais resultados. Esses casos devem ser tratados pelo algoritmo de coleta da rede.
2.1.2 – INSTAGRAM
A interface de desenvolvimento de aplicações do Instagram funciona de forma semelhante à do Facebook. Após registrar a aplicação na plataforma de desenvolvimento, o token é gerado para que o desenvolvedor possa fazer as requisições em sua aplicação. Assim como a API do Facebook, é baseada em requisições
HTTP e a busca de fotos na rede pode ser feita pela requisição com o seguinte formato:
|
1 |
https://api.instagram.com/v1/tags/query/media/recent?client_id=client_id&callback=callback_url |
Guia de início da API do Instagram
Para a requisição em questão, os parâmetros consistem do termo da consulta (query), da identificação da aplicação registrada (client_id) e do endereço de retorno da aplicação (callback_url). Assim como a API do Facebook, a resposta da requisição feita é um objeto no modelo JSON, com um conjunto de postagens (fotos) mais recentes de acordo com o termo buscado. É retornado também no mesmo objeto o endereço para a próxima página com os resultados da requisição, seguindo o mesmo processo necessário para coleta da plataforma anterior. Também é necessário o tratamento dos códigos de erro retornados pela requisição.
2.1.3 – TWITTER
O Twitter possui uma API de busca (Search API) que funciona de forma semelhante às das outras plataformas. Entretanto, na aplicação aqui desenvolvida, foi utilizada outra interface de programação do microblog: a Streaming API. O processo de autenticação segue da mesma forma: registrar a aplicação na plataforma de desenvolvimento do Twitter e obter o token de acesso para fazer as requisições. Entretanto,
diferentemente das requisições de busca, o método de coleta de dados da Streaming API consiste na escuta (por parte do coletor) à espera do recebimento de objetos (tweets) que contenham os termos da consulta, passados por parâmetro. Cada objeto retornado contém os atributos referentes ao tweet coletado (texto, autor, data, localização, dentre outros). A manipulação desse objeto e seus atributos se dá de acordo com a necessidade da aplicação.
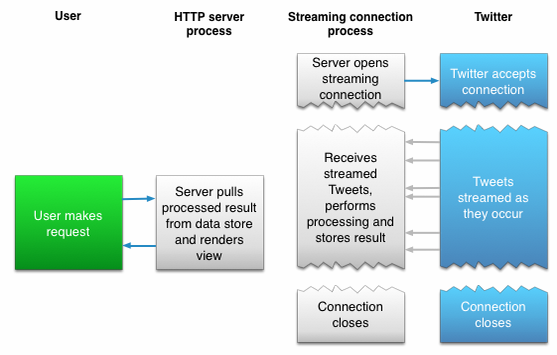 Fluxo das requisições na API do Twitter
Fluxo das requisições na API do Twitter
A vantagem da Streaming API em relação às anteriores é uma maior simplicidade em sua implementação, devido à ausência da necessidade de tratar as paginações, uma vez que se trata de uma coleta baseada na escuta momentânea das postagens. Por outro lado, como desvantagem nessa forma de coleta, há o fato de que os tweets são coletados somente no momento da escuta, que consiste ainda de apenas uma parcela do conjunto de todos os tweets disponíveis para a coleta naquele momento. Logo, não é possível fazer a coleta de tweets anteriores ao momento da escuta e a ocorrência de falhas na coleta faz com que os tweets transmitidos durante aquele período sejam perdidos. Apesar dessas desvantagens, seu uso se faz necessário em aplicações em que se deseja obter informações em tempo real, como a aplicação aqui desenvolvida.
2.2 – BANCO DE DADOS NÃO-RELACIONAL
Com o aumento da quantidade de dados gerados (principalmente devido às plataformas surgidas com a web 2.0), os bancos de dados relacionais, padrão tradicional para os SGDB’s mais conhecidos, mostraram-se ineficientes para a manipulação dessa grande quantidade de dados (Big Data). Afim de contornar esse problema, tornou-se comum a adesão ao modelo de dados não-relacional (NOSQL), principalmente por empresas que manipulam grandes quantidades de dados, como a Google, o Facebook, o Twitter, dentre
outras.
Um dos conceitos mais importantes presente no modelo de dados relacional consiste na normalização dos dados, que são divididos em diferentes tabelas, afim de evitar a redundância dos dados. Essa representação economiza significativamente em termos de armazenamento. No entanto, em termos de processamento, torna as consultas mais demoradas, uma vez que é necessária a junções de tabelas. No modelo nãorelacional, faz-se uso da repetição de dados em detrimento de consultas mais rápidas.
Outra questão importante que faz o modelo não-relacional mais adequado para algumas aplicações é a estrutura dos dados a serem armazenados. Os bancos de dados relacionais possuem uma estrutura bem definida, o que pode não ser desejável em algumas aplicações. No caso de postagens do Facebook, por exemplo, existem diversos atributos relacionados a uma postagem que podem (ou não) estar presentes em uma instância. Isso torna necessário uma grande quantidade de atributos na relação, que possivelmente
conterão valores nulos, resultando em uma tabela muito esparsa.
No modelo não-relacional, a estrutura não é bem definida, permitindo que cada objeto da coleção possua e armazene somente os atributos que tiverem valor definido. Além disso, o fato de muitos bancos de dados não relacionais armazenarem as coleções no formato JSON facilita a troca de informações do banco com a web. Para a aplicação aqui desenvolvida, por exemplo, uma vez que as postagens não possuem estrutura bem definida, a utilização do modelo não-relacional se mostra mais adequada. Ademais, o armazenamento
das requisições HTTP é trivial (uma vez que já estão no formato JSON). Para o objeto da API do Twitter, entretanto, foi necessário uma conversão para o modelo.
3 – REVISÃO DA LITERATURA
Com o crescimento do uso de redes sociais pelos usuários da web, e consequentemente da geração de dados por esses usuários, cresceu também o interesse na descoberta de conhecimento em cima desse conteúdo, devido ao volume e velocidade com que esses dados são gerados. Muitos trabalhos tem voltados suas pesquisas para esse contexto, servindo de apoio na construção da metodologia da aplicação a ser implementada por este trabalho.
A principal referência que originou a ideia desta aplicação foi o trabalho desenvolvido por (SANTOS et al.), que trata-se de um repositório online de informações a respeito de diversos temas, como as eleições presidenciais no Brasil, o campeonato brasileiro de futebol e inclusive sobre a dengue (assunto relacionado ao foco deste trabalho). O observatório de dados desenvolvido pelos autores exibe informações relevantes a respeito de cada tema, como por exemplo os assuntos mais disseminados, links mais populares, informações geográficas dos usuários, dentre outros.
A aplicação aqui desenvolvida, entretanto, busca apresentar informações de um foco específico não abordado pelos autores: além da dengue, são abrangidos também conteúdos disseminados a respeito das principais doenças, visando dar suporte patológico no controle de tais doenças. Além da coleta e exibição de informações, existe um processo intermediário importante na aplicação em questão, que trata da descoberta de conhecimento em cima dos dados coletados. Esse processo consiste em extrair conhecimentos que não são visivelmente triviais (como por exemplo, os usuários disseminadores de conteúdos mais influentes) através de técnicas apropriadas.
O trabalho desenvolvido por (CHAVES et al.) trata-se de uma aplicação web que realiza um processo semelhante ao descrito, que consiste da análise de sentimento do conteúdo propagado pelos usuários do Twitter a respeito de determinado tema. Apesar de possuir um foco muito específico, o formato da aplicação é bem próximo ao do observatório de dados, servindo como referência principalmente em termos de visualização das informações.
4 – ARQUITETURA DA APLICAÇÃO
A aplicação foi desenvolvida em uma máquina com sistema operacional Ubuntu 14.04. No backend da aplicação, os coletores foram implementados utilizando a linguagem de programação Python, e para armazenagem das postagens, foi utilizado o SGBD NoSQL MongoDB. Além disso, o frontend da aplicação consiste na visualização web do observatório, explorado pelo usuário, e para tal é necessário ainda um servidor web local que processe PHP, sendo utilizado o Apache em sua versão 2.4.7.
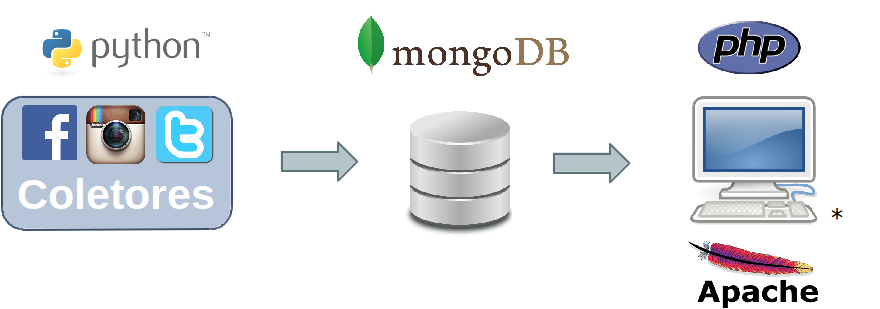
Arquitetura utilizada pela aplicação
Terminado o processo de desenvolvimento, no entanto, houve um processo de migração para um servidor web online. Utilizando o serviço de hospedagem grátis do http://www.1freehosting.com, a aplicação foi hospedada no endereço http://www.observatoriodasaude.pixub.com/, a fim de disponibilizá-la para uso e avaliação por parte de outros usuários.
4.1 – FUNCIONALIDADES
As funcionalidades providas pelo observatório são detalhadas abaixo. Elas foram implementadas de forma a subdivirem-se para cada uma das doenças observadas pela aplicação. Buscou utilizar-se o máximo dos recursos contidos nos objetos disponíveis pelas requisições das API’s. Ainda assim, existem informações sobre as postagens que podem vir a ser utilizadas em funcionalidades implementadas futuramente.
4.1.1 – MAPA DE USUÁRIOS
O twitter possui uma funcionalidade que permite ao usuário informar a localização de onde um tweet está sendo postado. Essa informação é recuperada na requisição à API da rede e armazenada no banco junto com os demais atributos do tweets. A fim de exibir essas informações geográficas de forma interpretável, foi utilizada a biblioteca do Google Maps para marcar essas localizações, conforme exemplifica a figura 4.
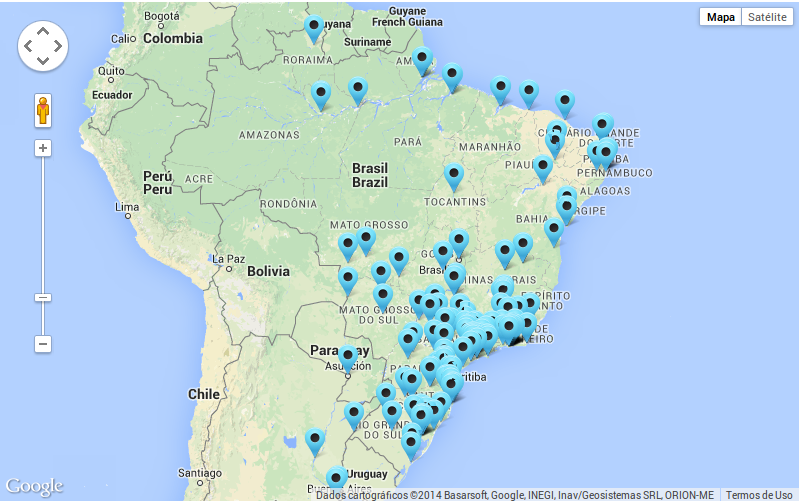
Distribuição geográfica dos usuários do Twitter
4.1.2 – SISTEMAS MAIS UTILIZADOS
Outra informação provida pelos tweets retornados pela API do Twitter consiste na fonte do tweet. Em suma, informa se o usuário postou o tweet através da aplicação web ou sua versão para o Android, iOS, Windows Phone e demais sistemas operacionais que forneçam suporte. Para os citados, que referem-se aos mais utilizados para navegação em redes sociais, fezse um levantamento da taxa de uso, a fim de se verificar os mais utilizados em cada contexto.
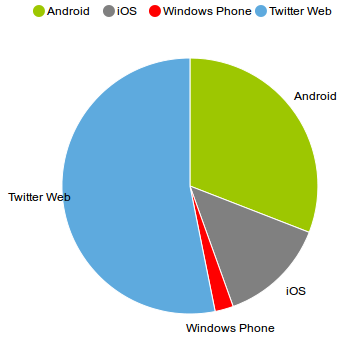
Sistemas mais utilizados pelos usuários do Twitter
4.1.3 – FOTOS MAIS CURTIDAS
Ainda buscando fazer um levantamento de tendências e itens populares disseminados nas redes, outra funcionalidade implementada exibe as 10 fotos mais curtidas no Instagram, referentes à doença em observação. A listagem é feita em ordem decrescente em relação ao número de curtidas, e a navegação pelas fotos pode ser feita sequencialmente pelos botões de próximo anterior, ou por acesso direto ao número da foto.
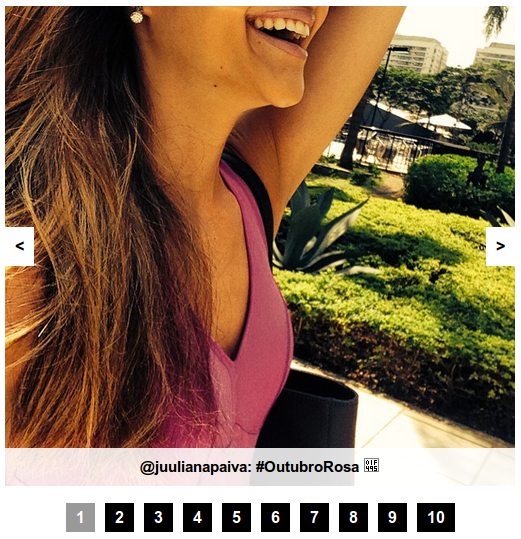
Fotos Mais Curtidas no Instagram
4.1.4 – TERMOS MAIS FREQUENTES
Uma funcionalidade que é comumente utilizada em estudos científicos consiste nos termos mais frequentes de determinado assunto. Esses termos mais frequentes permitem identificar relações entre outros assuntos com o assunto estudado, dada a alta frequência do termo. Essa funcionalidade foi implementada separadamente para cada uma das redes, utilizando-se os textos das postagens para fazer a contagem.
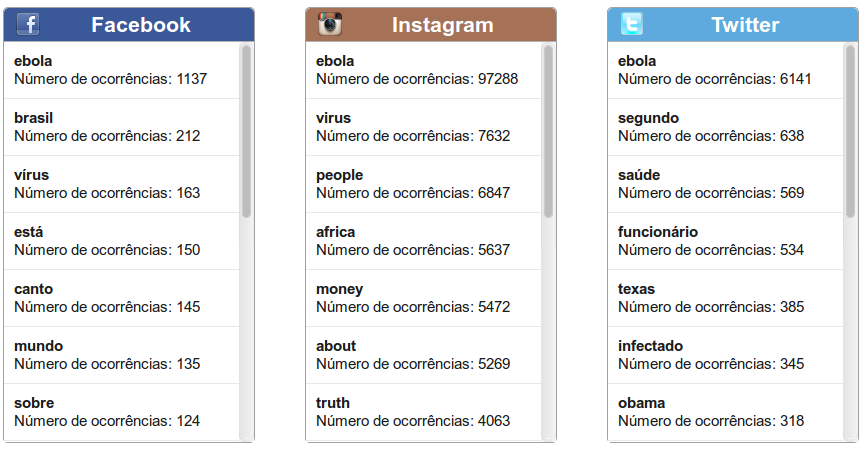
Funcionalidade de termos mais frequentes
4.1.5 – PESQUISAR TWEETS
A última funcionalidade implementada dá ao usuário a possibilidade de fazer consultas à coleção de tweets presentes no banco. Nessa consulta, é possível fazer filtros pelo nome de usuário do autor, o idioma do tweet publicado e pelo texto do tweet em si. Os 10 primeiros tweets retornados pela consulta são exibidos no box à direita.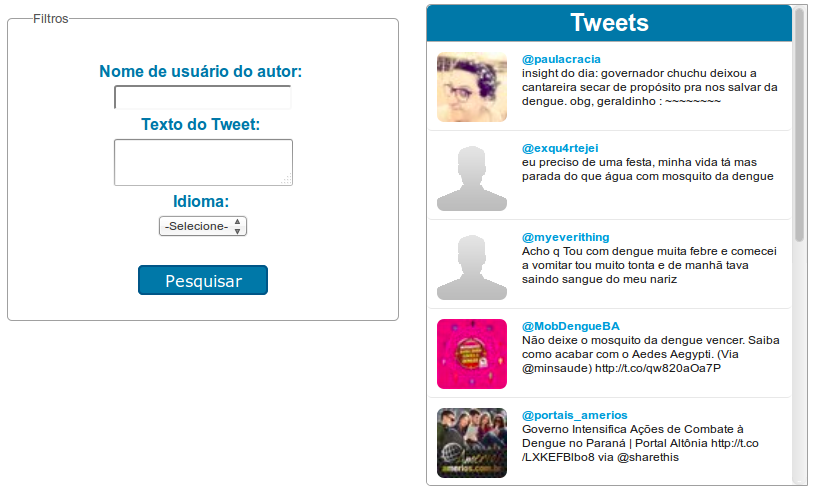
Funcionalidade de busca de tweets
5 – AVALIAÇÃO DA APLICAÇÃO
Devido à natureza da aplicação, sua avaliação mostrou-se complexa, devido a seu público-alvo restrito. A solução encontrada foi a opção de fazer entrevistas com potenciais usuários do sistema, que consistem no caso de 6 discentes do curso de Ciência da Computação na Universidade Federal de São João del-Rei. Após explorar a aplicação, o usuário respondeu a uma série de perguntas referentes sobre a aplicação e mais
especificamente sobre suas funcionalidades. Além da coleta de dados pessoais, as questões foram aplicadas com o auxílio do Google Forms. Dentre as conclusões levantadas pelos entrevistados, é válido destacar:
- Usuários estão aglomerados nas regiões mais habitadas: sul, sudeste e nordeste.
- Sistemas mais utilizados: Web e Android
- As fotos mais curtidas consistem de campanhas, notícias e informações disseminadas majoritariamente por pessoas famosas
- Termos mais frequentes distintos, sendo correlatos apenas os nomes das doenças
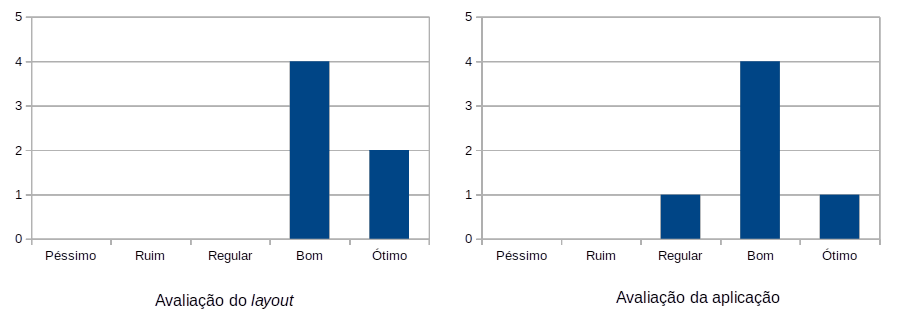
Quanto à avaliação quantitativa referente à opinião dos usuários sobre o layout e o cumprimento de seu propósito por parte da aplicação, os gráficos abaixo exibem o resultado:
6- CONSIDERAÇÕES FINAIS
O observatório da saúde faz parte de uma série de aplicações que busca fazer uso da grande quantidade de dados que vem sido gerados pela interação dos usuários com a Web. A avaliação com os usuários revelou observações e conhecimentos pertinentes com relação aos dados coletados. Em contrapartida, esse é um tipo de aplicação difícil de se manter, devido ao alto custo em termos de processamento e memória.
Por fim, como trabalhos futuros, sugere-se a inserção de informações sobre as doenças presentes no observatório (prevenção, diagnóstico e tratamento). Além disso, o Facebook foi pouco explorado nas funcionalidades implementadas, havendo abertura para novas aplicações. A implementação de novas funcionalidades no observatório possibilita uma extração mais ampla de conhecimentos acerca dos dados analisados.
2 Comentários
Sannytet
11 de dezembro de 2018 at 17:06Nice posts! 🙂
___
Sanny
Cadu
17 de Fevereiro de 2021 at 17:20Topper, posta mais conteúdos sobre data science pá nóis!