
Nota: Este artigo foi desenvolvido para a disciplina de ‘Métodos e aplicações de Ranking’ pelo mestrado da UFSJ, sob orientação do professor Vinícius Vieira. O código-fonte da implementação em python pode ser obtido aqui.
Estamos constantemente desempenhando a tarefa rearranjar um determinado grupo de itens sob algum critério de importância. Seja para definir os melhores discos do ano, melhores séries de determinado serviço de streaming ou mesmo os livros favoritos da biblioteca pessoal, essa é uma demanda que comumente desempenhamos de forma instintiva sob critérios que muitas vezes não estão muito claros ou muito menos quantificáveis. Ao analisarmos formas particulares de avaliar determinado conjunto é importante, portanto, ter em mente que esses métodos de classificação o fazem sempre tendo em foco determinado critério, nunca se tratando de um ranking definitivo. Tendo esse pano de fundo em mente, a tarefa de rankear determinado grupo se resume a ordená-lo segundo determinado score atribuído.
O campeonato brasileiro, competição esportiva de maior visibilidade nacional, há alguns anos vem determinando sua pontuação com base no número de vítorias/empates/derrotas (mais critérios de desempate) de suas equipes, que realizam jogos de ida e volta com os demais times. Em situações com essa estrutura onde os elementos do conjunto realizam confrontos entre si, algumas outras formas de se avaliar esses confrontos se apresentam na literatura. Aqui neste post, vamos explorar os métodos de ranking de Massey e de Colley, aplicados a uma base com os dados de jogos do campeonato brasileiro entre 2000 e 2021, disponibilizados aqui. A implementação será demonstrada na linguagem python, com o auxílio das bibliotecas pandas e numpy.
Método de Massey
O Método de Massey, criado pelo professor de matemática Kenneth Massey enquanto um estudante de graduação no Bluefield College em 1997, é um dos métodos atualmente usados pelo Bowl Championship Series, um sistema de classificação que determina quais os scores dos times do futebol universitário da NCAA. Esse método faz uso da diferença de pontos (que em um jogo de futebol se dá como gols feitos menos gols sofridos) e as classificações obtidas também podem ser desenvolvidas para produzir um score ofensivo e defensivo para cada equipe. Em suma, para qualquer jogo entre a equipe i e a equipe j, o diferencial de pontos para a equipe i é a pontuação da equipe i menos a pontuação da equipe j. Em qualquer ponto de um torneio, o ponto diferencial para a equipe i será a soma de seus diferenciais de pontos para os jogos que disputou. ilustrar um exemplo, vamos tomar como base o seguinte cenário de confrontos, da NCAA 2005:
| Duke | Miami | UNC | UVA | VT | V-D | Dif | |
| Duke | 7-52 | 21-24 | 7-38 | 0-45 | 0-4 | -124 | |
| Miami | 52-7 | 34-16 | 25-17 | 27-7 | 4-0 | 91 | |
| UNC | 24-21 | 16-34 | 7-5 | 3-30 | 2-2 | -40 | |
| UVA | 38-7 | 17-25 | 5-7 | 14-52 | 1-3 | -17 | |
| VT | 45-0 | 7-27 | 30-3 | 52-14 | 3-1 | 90 |
Para este exemplo, podemos obter um vetor de rankings através do sistema Mr = p , dado como:
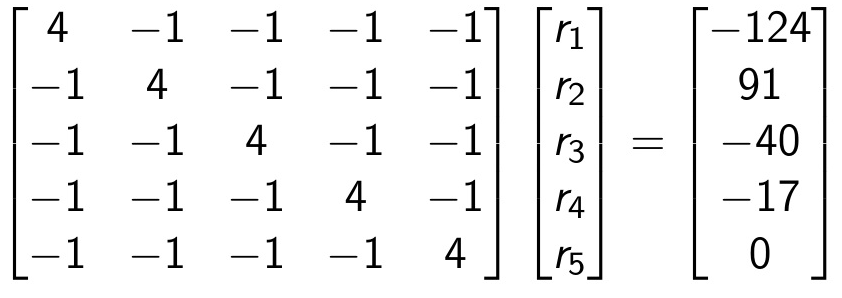
Onde o vetor p é o vetor das diferenças nos pontos (tabela anterior), o vetor r é o vetor a ser obtido onde cada posição i corresponde ao rating do time correspondente, e a matriz M é preenchida seguindo as regras:
- Os elementos da diagonal principal Mii guardam o número de jogos realizados pelo time i
- Os elementos fora da diagonal principal Mij , i ≠ j, guardam a negação do número que um time i jogou contra um time j.
- No caso em questão, como cada time jogou uma vez com todos os outros times, sua negação fora da diagonal principal contém sua negação (-1), enquanto a diagonal principal contém os 4 jogos de cada time.
- Por definição, as linhas de M somam zero (linearmente dependentes). Para que a matriz seja rank completa, substituímos a última linha de M por 1 e a última posição de p por 0.
A solução do sistema é dada por:
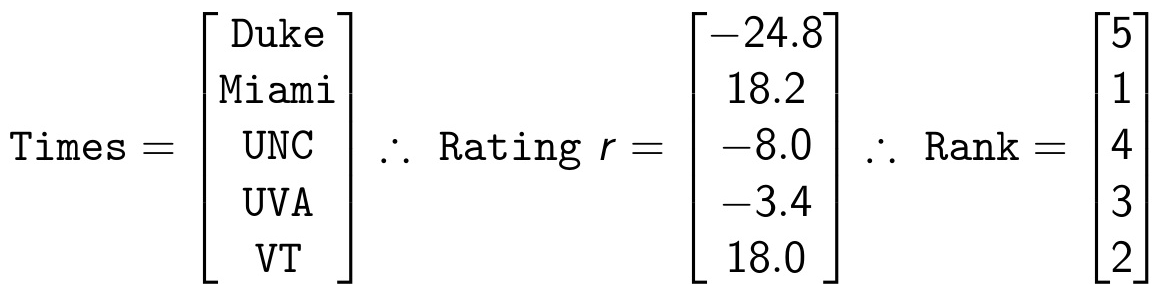
No exemplo a ser trabalhado, o ranking dos times do campeonato brasileiro pode ser calculado como mostra o código abaixo, utilizando o auxílio das bibliotecas pandas e numpy , voltadas para aplicações em de ciência de dados:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
import numpy as np import pandas as pd from pre_processamento import * import sys #Preparando o data frame dfCampeonato = pd.read_csv("campeonato-brasileiro-full.csv", delimiter=";") dfCampeonato['Data'] = pd.to_datetime(dfCampeonato['Data'], format='%d/%m/%Y') dfCampeonato = dfCampeonato.applymap(str); dfCampeonato["Placar"] = dfCampeonato["Mandante Placar"].map(str) + "x" + dfCampeonato["Visitante Placar"] #Datas dos jogos - preciso verificar o ano de 2020 pois o campeonato se estendeu ate fev/2021 data_inicio = sys.argv[1]+'-01-01' if int(sys.argv[1])==2020: data_fim = '2021-02-28' else: data_fim = sys.argv[1]+'-12-31' #Preparando alguns dados/indicadores brasileiro_ano = dfCampeonato[(dfCampeonato['Data'] > data_inicio) & (dfCampeonato['Data'] < data_fim)] clubes = pd.concat([brasileiro_ano['Mandante'].str.lower(), brasileiro_ano['Visitante'].str.lower()], axis=1, keys=['Clubes']) clubes_lista = pd.Series(clubes['Clubes'].unique(), name="Clubes") clubes_lista = clubes_lista.to_frame() tabelaCampeonato = fillTable(clubes_lista, brasileiro_ano) n_times = len(clubes_lista) n_rodadas = brasileiro_ano["Rodada"].astype(int).max() n_jogos_por_time = n_rodadas/(n_times-1) #Massey M = np.full((n_times, n_times), n_jogos_por_time*-1) np.fill_diagonal(M,n_rodadas) ultima_linha = a=np.empty(n_times); a.fill(1) M[-1] = ultima_linha p = np.array(tabelaCampeonato['SG']) p[-1] = 0 r = np.linalg.solve(M,p) |
O método de Massey avança ainda para calcular não somente um score geral para cada time, mas também seus índices de ataque ( o – offense) e defesa ( d – defense). A partir do sistema original, podemos escrever a matriz M como a diferença de duas matrizes T e P, onde a primeira contém os elementos fora da diagonal principal, enquanto a última contém os elementos principais. Substituindo no sistema anterior e desenvolvendo algebricamente:
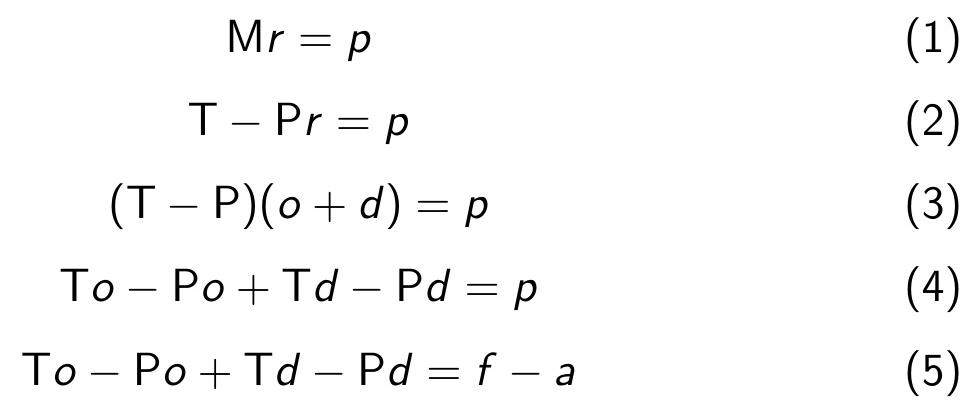
Agora a equação obtida em (5) pode ser dividida em:
- To – Pd = f
- Po – Td = a
A primeira equação diz que o total de pontos marcados por um time pode ser obtido pela multiplicação do score de ataque pelo número de jogos realizados subtraído pela soma dos scores de defesa dos seus oponentes. Trabalhando apenas com To -Pd = f para resolver o e d , temos:
|
1 2 3 |
To - Pd = f T(r-d) - Pd = f (T+P) = Tr - f |
De onde temos que Tr -f é um vetor de constantes se r já estiver calculado. Assim, o método de Massy para encontrar d (dado r ) fica: (T+P)d = Tr - f (este lado já resolvido). Uma vez que resolvemos e temos r e d disponíveis, o pode ser computado utilizando a equação r = o+d . Para o dataframe que estamos trabalhando, esses valores podem ser obtidos como demonstra o código abaixo:
|
1 2 3 4 5 6 7 8 9 10 11 |
T = np.full((n_times, n_times), 0) np.fill_diagonal(T,n_rodadas) P = np.full((n_times, n_times), n_jogos_por_time) np.fill_diagonal(P,0) Tr = T.dot(r) f = np.array(tabelaCampeonato["GP"]) d = np.linalg.solve(T+P,Tr-f) o = r - d |
Método de Colley
O método de classificação de Colley, que foi usado nas classificações BCS antes da mudança no sistema, é uma modificação do método mais simples de classificação, de porcentagem de vitórias. O método de Colley nos dá, de forma semelhante, um score para cada equipe, que podemos usar para encontrar uma classificação para as equipes. A porcentagem de vitórias é o principal método de rating para a maior parte das ligas. Entretanto, esse sistema possui algumas falhas:
- Empates nas notas ocorrem com frequência em esportes onde os times jogam a mesma quantidade de vezes com os mesmos times
- A força dos oponentes não é considerada na análise (derrotar o oponente mais fraco na liga traz a mesma pontuação que derrotar o mais forte)
- Times que não vencem ficam com nota 0 (não reflete de fato a realidade)
O método de Colley começa com uma pequena modificação na porcentagem de vitórias, tal que:
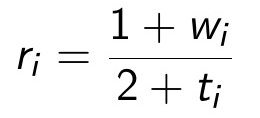
Onde o vetor de ratings r do time i é obtido em função da quantidade de vitórias e jogos totais como w e t , respectivamente. Essa modificação, embora modesta, traz uma série de vantagens:
- Em vez de iniciar com o rating ininterpretável 0, cada time começa com 1/2.
- Se um time perde o primeiro jogo, sua nota cai para 1/3, o que Colley argumenta que faz muito mais sentido que 0.
- Um time deve receber uma recompensa maior do que por enfrentar um time mais fraco, uma vez que a nota a ser obtida está relacionada à nota de seu oponente
Na representação matricial, para obtermos um sistema, a equação de Colley pode ser escrita de maneira compacta como Cr = b , onde:
- r é o vetor de incógnitas, de tamanho n
- b é o vetor de termos independentes de tamanho n tal que bi = 1 + (wi – li)/2
- C é a matriz de coeficientes definida por:
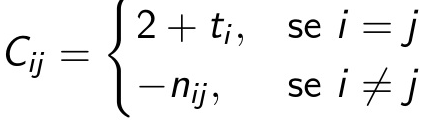 Onde nij é o número de vezes que o time i jogou com o time j. Utilizando o exemplo anterior da liga NCAA, o sistema seria montado da seguinte forma:
Onde nij é o número de vezes que o time i jogou com o time j. Utilizando o exemplo anterior da liga NCAA, o sistema seria montado da seguinte forma:
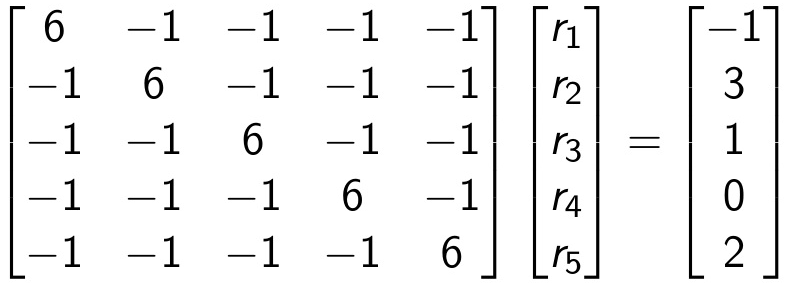
Resolvendo o sistema, temos:
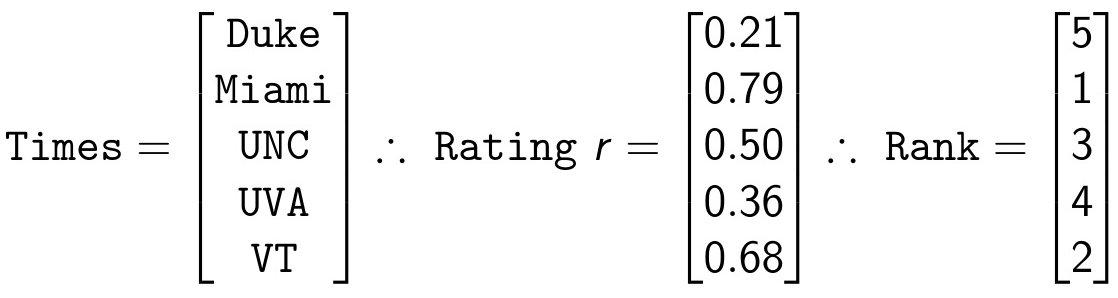
Para aplicar esses conceitos e obter os ratings na base do campeonato brasileiro, a implementação segue assim:
|
1 2 3 4 |
C = np.full((n_times, n_times), n_jogos_por_time*-1) np.fill_diagonal(C,n_rodadas+2) b = np.array(1+(tabelaCampeonato["V"]-tabelaCampeonato["D"])/2) r = np.linalg.solve(C,b) |
Como no método de Massey, o vetor r obtido contém os ratings de cada time, que possibilitam a ordenação para obter a classificação segundo o método.
Executando o script python
No código disponibilizado para download, o arquivo principal pode ser executado da seguinte forma:
|
1 |
python main.py ano_do_campeonato |
Para o ano de 2019, por exemplo, obtemos a seguinte saída:
| # | Clubes | PG | J | V | E | D | GP | GC | SG | r – Massey | o | d | r – Colley |
| 1 | Flamengo | 90 | 38 | 28 | 6 | 4 | 86 | 37 | 49 | 1.22 | 1.68 | -0.45 | 0.78 |
| 2 | Santos | 74 | 38 | 22 | 8 | 8 | 60 | 33 | 27 | 0.675 | 0.98 | -0.31 | 0.66 |
| 3 | Palmeiras | 74 | 38 | 21 | 11 | 6 | 61 | 32 | 29 | 0.725 | 1.01 | -0.28 | 0.67 |
…
Na amostra acima é possível verificar, por exemplo, que segundo ambos os rankings, o Palmeiras teria ultrapassado o Santos em sua classificação. Outros anos como 2009 e 2020, cuja disputa do campeonato se estendeu até a última rodada, também vale a análise e interpretação dos resultados. Quaisquer dúvidas ou sugestões, por favor utilize a área de comentários ou entre em contato!
Nenhum Comentário