
Um Web Crawler (também conhecido como spider) é um algoritmo que navega pela web com a finalidade de extrair informações sobre um conteúdo em específico. Essa forma automatizada de navegar faz a mineração de dados a partir de uma lista de fontes (chamadas de seeds), fazendo a extração (parsing) do conteúdo para uma estrutura bem definida. Um exemplo de aplicação desse algoritmo seria a mineração de postagens em blogs ou portais de notícia. Vou demonstrar neste post um exemplo de implementação de web crawler para notícias do blog A Casa do Cogumelo, mas pode ser estendido para outros blogs que tenham sido desenvolvidos utilizando WordPress, uma vez que a estrutura de classes é padronizada.
Existem algumas bibliotecas que facilitam a navegação e o parsing de informações em páginas web. Na linguagem Ruby, o Nokogiri é comumente a opção principal dos desenvolvedores. Uma possível alternativa seria a biblioteca Mechanize, disponível não só em Ruby, mas também em Python. O Nokogiri pode ser facilmente instalado a partir da gema:
|
1 |
gem install nokogiri |
Além de declarar o uso das gemas Nokogiri e OpenURI (disponível por padrão no Ruby), é declarado no início um conjunto de endereços das categorias que serão exploradas pelo crawler. Encorajo fazer um acesso a esses endereços e inspecionar o HTML da página para entender sua estrutura, uma vez que essa compreensão é primordial para desenvolver uma solução para recuperação das informações desejadas.
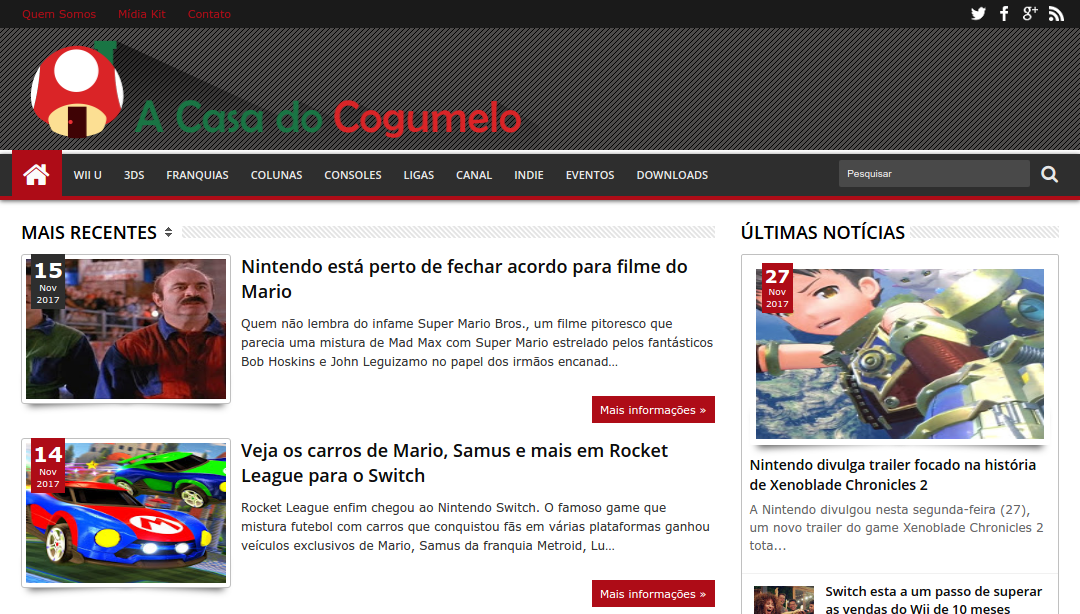
Exemplo de Categoria – Super Mario
Inspecionando o HTML da seção onde listam-se os posts, foi identificado que a DIV utiliza sempre a classe “post-summary”. Dentro dessa DIV, desejamos recuperar todos os links contidos nela, que são referências para o post da categoria em questão, cujos endereços serão visitados para extração do título e conteúdo da postagem.
O CÓDIGO-FONTE
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
#! /usr/bin/env ruby require 'nokogiri' require 'open-uri' categorias_urls = [ "http://www.acasadocogumelo.com/search/label/Mario", "http://www.acasadocogumelo.com/search/label/Pok%C3%A9mon", "http://www.acasadocogumelo.com/search/label/Donkey%20Kong", "http://www.acasadocogumelo.com/search/label/Zelda" ] categorias_urls.each do |url| # Fetch and parse HTML document doc = Nokogiri::HTML(open(url)) #Pegando a lista de posts disponíveis na categoria posts_summary = doc.css(".post-summary").search("strong").search("a").map{|a| [a.attributes["title"].value, a.attributes["href"].value]} #Extraindo as informações de cada post posts_summary.each do |post| titulo_post = post[0] link_post = post[1] post = Nokogiri::HTML(open(link_post)) post_body = post.css(".post-body.entry-content").first.inner_html end end |
O código para obtenção dos dados desejados nesse caso é curto e bem compacto, já que o blog em questão foi desenvolvido utilizando WordPress e portanto possui uma estrutura bem definida. A linha de código mais complexa e que requer atenção especial é a que faz a extração dos links:
|
1 |
posts_summary = doc.css(".post-summary").search("strong").search("a").map{|a| [a.attributes["title"].value, a.attributes["href"].value]} |
No Documento aberto, ele procura pela classe “post-summary”, que se refere à DIV que contém os links. Tais links, por sua vez, estão aninhados dentro de tags <STRONG>, por isso a busca sequencial dentro dessa DIV. Nesse conjunto de links, aplica-se a função de mapeamento para obter, para cada link, o seu título e seu endereço, localizados nas primeira e segunda posições do array, respectivamente. A partir dos links obtidos, o algoritmo faz as iterações para obter o conteúdo da postagem, que pode ser obtido pelo HTML interno da div com classe “post-body entry-content”:
|
1 |
post_body = post.css(".post-body.entry-content").first.inner_html |
É válido ressaltar que, nesse caso, o conteúdo retornado contém tags HTML, que devem ser removidas se desejado. Para o caso de querer persistir esse conteúdo em um banco de dados, é importante também tomar o cuidado de sanitizar o conteúdo obtido, a fim de evitar erros de sintaxe causados por aspas simples e duplas, bem como evitar possíveis injeções de código. Quaisquer dúvidas ou sugestões, utilize os comentários ou entre em contato!
4 Comentários
Kidizinho
18 de dezembro de 2017 at 13:26Good job! Valeu pelo tutorial. Quais as vantagens dessa biblioteca nokogiri em relação a outras de outras linguagens, por exemplo o beautifulsoup do Python? Valeu!
Ronan Lopes
18 de dezembro de 2017 at 13:42Muito obrigado, “KIDIZINHO”! A escolha da biblioteca que você vai utilizar depende muito da sua aplicação. No meu caso, estava desenvolvendo uma aplicação em Rails, e portanto optei pela gem Nokogiri. No propósito geral, Python é comumente muito recomendado para navegação/mineração web. Citei a Mechanize no post, mas a Beautiful Soup é uma excelente referência também, assim como JSoup para Java. Neste, infográfico, você pode ver uma breve comparação entre Ruby, Python e R: https://cdn-ssl-promptcloud.pressidium.com/wp-content/uploads/2016/05/ruby-vs-python-vs-r-infographic-768×3952.png
KIDIZINHO
20 de dezembro de 2017 at 06:09Entendi. Obrigado pelo link!
Sannytet
12 de dezembro de 2018 at 02:58Nice posts! 🙂
___
Sanny