
Nota: este artigo foi desenvolvido em parceria com Maria Eduarda Lacerda (dudapazeli91@gmail.com) e Pedro Sarmento (pedro.hpsarmento@gmail.com) pela disciplina de Redes de Computadores, do curso de Ciência da Computação pela Universidade Federal de São João del-Rei (UFSJ), sob a orientação do Professor Rafael Sachetto (sachetto@ufsj.edu.br). O código-fonte da implementação pode ser obtido aqui.
1 – INTRODUÇÃO
Posicionada entre as camadas de aplicação e de rede, a camada de transporte é uma peça central da arquitetura de rede em camadas pois desempenha o papel fundamental de fornecer serviços de comunicação diretamente aos processos de aplicação que rodam em máquinas diferentes. Isto é, fornece uma comunicação lógica entre estes processos. Sendo assim, os processos de aplicação utilizam a comunicação lógica provida pela camada de transporte sem a preocupação com os detalhes da infraestrutura física utilizada para transportar a mensagem.
Os protocolos da camada são executados nos sistemas finais em que o pacote de mensagens recebidas por um processo de aplicação é convertido em pacotes de camada de transporte, ou segmentos. Isso é feito fragmentando as mensagens da aplicação em pedaços menores e adicionando-se um cabeçalho de camada de transporte a cada pedaço. A camada de transporte passa cada segmento para a camada de rede onde ele é encasulado em um datagrama e enviado ao destinatário. No lado receptor, a camada de rede extrai o segmento do datagrama e passa-o para a camada de transporte.
Em seguida, essa camada processa o segmento recebido disponibilizando os dados para a aplicação destinatária. Os dois protocolos mais importantes dessa camada são o UDP e TCP, que visam aplicações de comportamentos difereentes. Enquanto o TCP garante entrega confiável, controle de fluxo e entrega sequencial dos dados, o UDP não fornece nenhuma dessas garantias, sendo utilizada em aplicações onde não há preocupação com esses requisitos, como resolução de nome de servidor (DNS) ou streaming de vídeos.
Este trabalho visa implementar um protocolo que garanta entrega confiável de dados sobre UDP. Para isso devem ser definidos quais serão os campos de cabeçalho do pacote que encapsulará os dados do arquivo. As seções seguintes apresentam os fundamentos necessários para a implementação, bem como os problemas e as decisões
tomadas.
2 – O PROBLEMA
O programador de aplicações para a Internet que opta pelo UDP como seu protocolo de transporte tem um trabalho adicional, se compararmos com o TCP. O UDP, bem como o IP é um protocolo não-confiável, não-orientado a conexão. Assim, o UDP permite que todos os problemas eventualmente surgidos na rede IP se estendam à camada de aplicação. O programador tem que, portanto, projetar sua aplicação para detectar se os dados: (1) se perderam, (2) duplicaram, (3) chegaram fora de ordem; e tomar as medidas necessárias para resolver estes problemas.
Este trabalho prático visa implementar um protocolo confiável sobre UDP para uma aplicação cliente-servidor. Na aplicação, cada datagrama UDP/IP carrega um número inteiro positivo que identifica a ordem sequencial do datagrama. O identificador do primeiro pacote é escolhido aleatoriamente. O último datagrama tem identificador -1.
O cliente tem uma interface que permite que o usuário escolha se quer (1) perder dados, (2) duplicar dados, (3) embaralhar dados. Se a opção é perder ou duplicar dados, deve ser adotada uma estratégia aleatória para escolher quais dados são perdidos ou duplicados. Se a opção é perder os dados, o servidor deve fazer um pedido explícito de
retransmissão. O servidor deve imprimir os dados que recebeu (com dados perdidos, duplicados, fora de ordem) bem como os dados corretos, com todos os problemas resolvidos.
Os fundamentos teóricos sobre o protocolo da camada de transporte, bem como o protocolo confiável de transferência de dados serão apresentados a seguir. Nas seções seguintes serão explicitados detalhes de implementação da aplicação, como estrutura de dados, estratégias tomadas, dentre outros.
3 – O PROTOCOLO UDP
O UDP é um protocolo da camada de transporte. Trata-se de um serviço de entrega sem conexão, porque não há necessidade de manter um relacionamento longo entre cliente e o servidor. Assim, um cliente UDP pode criar um socket, enviar um datagrama para um servidor e imediatamente enviar outro datagrama com o mesmo socket para um servidor diferente. Da mesma forma, um servidor poderia ler datagramas vindos de diversos clientes, usando um único socket.
O protocolo UDP é normalmente utilizado por aplicações que exigem um transporte rápido e contínuo de dados entre equipamentos. Enquanto no protocolo TCP é dado como prioridade à conexão e a chegada correta dos dados no destino, o UDP não verifica o recebimento e a integridade dos dados enviados. Os dados são transmitidos apenas uma vez, incluindo apenas um frágil sistema de CRC. Os pacotes que chegam corrompidos são simplesmente descartados, sem que o emissor fique sabendo do problema.
O protocolo UDP e TCP têm poucas diferenças: básica é que o TCP é um protocolo orientado à conexão, que inclui vários mecanismos para iniciar e encerrar a conexão, negociar tamanhos de pacotes e permitir a retransmissão de
pacotes corrompidos. O UDP por sua vez é feito para transmitir dados pouco sensíveis, como streaming de áudio e vídeo. No UDP não existe checagem de nada, nem confirmação alguma.
Em resumo, em aplicações em que é preferível entregar os dados o mais rapidamente possível, mesmo que algumas informações se percam no caminho, como o caso das transmissões de vídeo pela internet(streaming), onde a perda de um pacote não interromperá a transmissão, o UDP se torna mais indicado que o TCP.
4 – CONCEITOS DE ENTREGA CONFIÁVEL DE DADOS (RDT)
Dentre todos os problemas que existem para a implementação de redes de computadores, podemos dizer que a transferência confiável de dados é um dos principais. Essa tarefa ainda é mais complexa, pois a implementação do Protocolo de transferência confiável de dados é feita em um canal confiável, porém possui a camada de rede logo
abaixo: um canal não confiável.
Com um canal confiável, nenhum dos dados transferidos é corrompido ou perdido, e todos são entregues na ordem em que foram enviados. É responsabilidade de um protocolo de transferência confiável de dados implementar essa abstração de serviço. Será mostrada nessa seção um série de protocolos que vão se tornando cada vez mais complexos, até chegar a um protocolo de transferência confiável de dados impecável. Esse protocolo é chamado rdt (reliable data transfer, ou transferência confiável de dados).
4.1 – RDT 1.0
Nesta versão mais simples do protocolo, é considerado o caso em que o canal de transferência é completamente confiável. Simplesmente não há diferença entre unidade de dados e um pacote. Além disso, todo o fluxo de pacotes ocorre do remetente para o destinatário e por ser uma canal totalmente confiável, não há necessidade de o destinatário fornecer qualquer informação ao remetente.
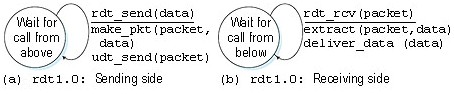
Figura 1: Protocolo RDT 1.0: lados remetente e destinatário
No lado do remetente rdt simplesmente aceita dados da camada superior pelo evento rdt_send(data), cria um pacote que contém os dados e envia-o para dentro do canal. Do lado destinatário, rdt recebe um pacote pelo evento rdt_rcv(packet), extrai os dados do pacote e os passa pela camada superior.
4.2 – RDT 2.0
Neste modelo mais complexo, é considerado um canal em que os bits do pacote podem ser corrompidos. Esses erros podem acontecer, por exemplo, normalmente nos componentes físicos da rede enquanto é transmitido o pacote. Entretanto, ainda neste protocolo, é feita uma suposição de que todos os pacotes transmitidos sejam recebidos pelo destinatário na ordem em que foram enviados.
Para lidar com a possível presença de erros as seguintes propriedades são exigidas:
- Detecção de erros: É preciso que o destinatário detecte quando erros de bits acontecem. Para isso, são usadas técnicas em que o remetente envie, além dos bits do dado original, bits extras que permitam ao destinatário detectar o erro.
- Realimentação do destinatário: Partindo da ideia de que quase sempre destinatário e remetente estão rodando em sistemas finais diferentes, possivelmente a milhares de quilômetros, a única maneira do remetente sabe se um pacote chegou ao seu destino final, é o destinatário fornecer um feedback ao remetente. NAKs e ACKs são exemplos desses feedbacks. O protocolo rdt2.0 fornece essa resposta do destinatário
para o remetente.
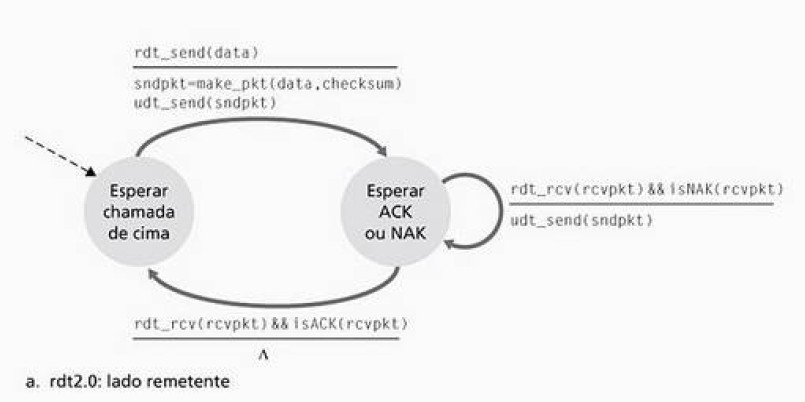
Figura 2: Protocolo RDT 2.0: lado remetente
O lado remetente do rdt2.0 tem dois estados: no estado mais a esquerda, o protocolo está esperando que os dados sejam passados pela camada superior. Quando o evento rdt_send(data)ocorrer, o remetente criará um pacote contendo os dados a serem enviados juntamente com a soma de verificação do pacote. O estado da direita fica então esperando um pacote ACK ou NACK do destinatário. Caso chegue um pacote ACK, o remetente saberá que o pacote mais recente chegou ao destinatário. Se um NAK for recebido, o protocolo retransmitirá o ultimo pacote e esperará por uma nova resposta do destinatário. Enquanto o remetente espera por uma resposta, não pode receber mais dados da camada superior.
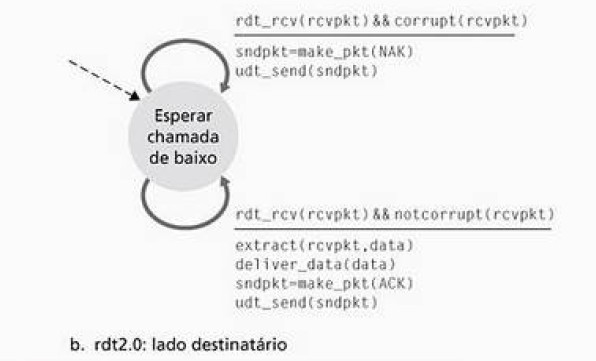
Figura 3: Protocolo RDT 2.0: lado destinatário
O lado destinatário do protocolo rdt2.0 tem apenas um estado, parecido com o rdt1.0. Quando o pacote chega, ele responde um com um ACK ou NAK dependendo do estado do pacote recebido. O rdt2.0 funciona, mas ainda possui defeitos não desejáveis para o funcionamento total da entrega de confiável de dados. Um destes defeitos é não considerar a possibilidade de corrupção nos pacotes NAK e ACK. Uma solução simples para este problema é adicionar um novo campo ao pacote de dados e fazer com que o remetente numere seus pacotes de dados colocando um número de sequencia nesse campo. O destinatário tem então que verificar esse número para determinar se um pacote é uma retransmissão ou não. Essa versão corrigida do rdt2.0 é o rdt2.1.
4.3 – RDT 2.1
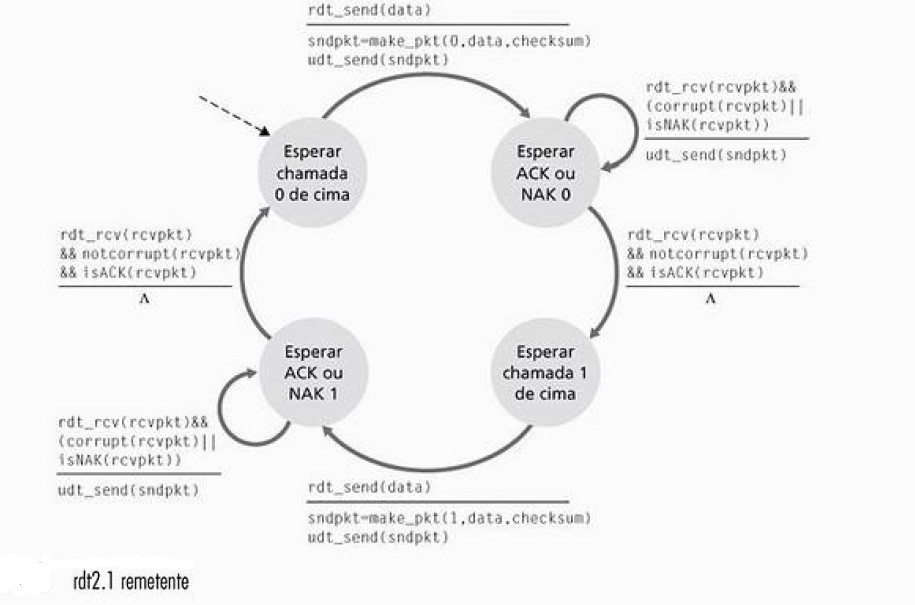
Figura 4: Protocolo RDT 2.1: lado remetente
Cada uma das FSM do rdt2.1 tem um número dobrado de estados em relação ao rdt2.0. Isso porque o estado do protocolo agora deve saber se o pacote que está sendo enviado pelo remetente (e aguardado pelo destinatário) possui número de sequência 0 ou 1.
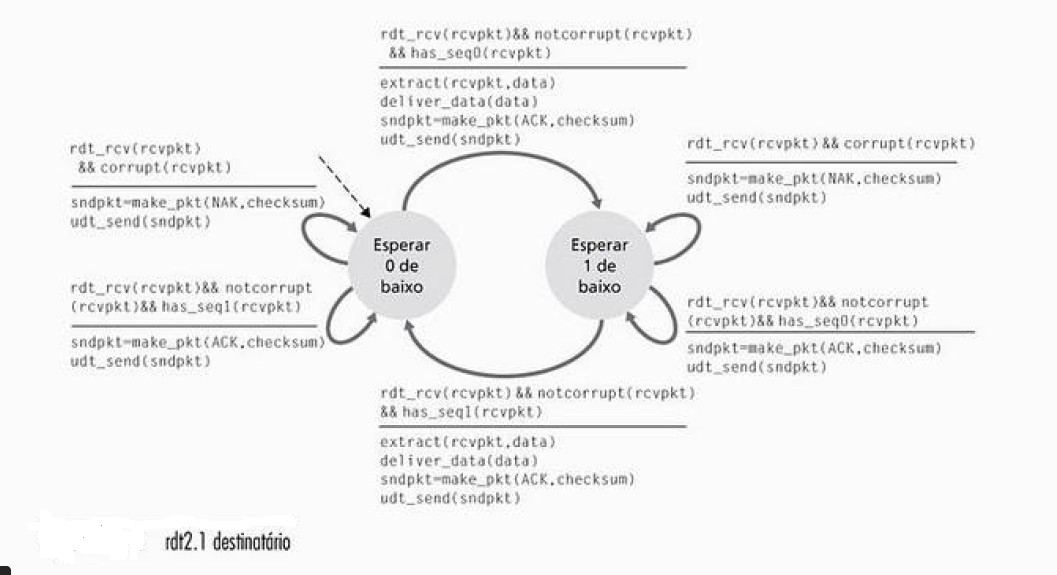
Figura 4: Protocolo RDT 2.1: lado remetente
Quando um pacote fora de ordem é recebido, é enviado um ACK para o remetente, caso o pacote esteja corrompido um NAK é enviado. Um remetente que recebe dois ACKs para o mesmo pacote, sabe que o destinatário não recebeu corretamente o pacote seguinte.
4.4 – RDT 2.2
Uma melhoria sutil implementada no rdt2.1, foi uma transferência confiável de dados sem NAK. Nesse novo protocolo rdt2.2, o destinatário deve incluir o número de sequência do pacote que está sendo reconhecido por uma mensagem ACK e o remetente deve verificar o número de sequencia do pacote que está sendo reconhecido também por uma mensagem ACK.
Para tornar o problema mais real, supor que além de corromper bits, o canal de transferência possa perder pacotes. Mais duas funcionalidades devem ser adicionadas: como detectar perda de pacote e o que fazer quando isso ocorre. Isso é tratado na versão 3.0 do protocolo.
4.5 – RDT 3.0
O rdt 3.0 é o mais completo ele utiliza uma temporizador de contagem regressiva para casos em que o remetente fique esperando um ACK sem saber se ele foi perdido no meio do caminho ou se esta muito atrasado ou até mesmo se o pacote nem chegou no destino. Nesse casos o temporizador assume um valor considerável, onde ele não pode
ser nem muito pequeno por questão de atraso de ida e volta e nem muito grande onde otempo de detecção de pacote perdido seria demorado de mais.
5 – IMPLEMENTAÇÃO
A aplicação cliente-servidor implementada provê a transferência confiável baseado no protocolo rdt 2.2. Nesta versão do protocolo, não se usa implementa a detecção de perda de pacotes (tanto de dados quanto ACKs) por meio de um temporizador. Adicionando-se essa funcionalidade, teria-se o protocolo rdt 3.0 implementado.
Para implementar a aplicação cliente-servidor com os requisitos apresentados, utilizou-se a linguagem de auto nível python, por esta ser eficiente no tratamento de cabeçalhos, strings e outras estruturas necessárias para o problema. Utilizou-se a biblioteca socket da linguagem para fazer-se a comunicação entre cliente e servidor,
sendo que ambos executam em máquina local. Nas seções abaixo segue uma explicação disjunta da implementação de servidor e cliente.
5.1 – O SERVIDOR
Para se comunicar com a aplicação cliente, os primeiros passos no servidor são criar o socket por onde será feita a comunicação entre os processos. Após criar o socket, e amarrá-lo ao endereço (localhost) e porta (definida como 5000 por ser um número de porta alta, disponível para uso), o processo servidor fica em escuta para receber os dados do cliente. Ao receber um pacote do cliente, o servidor faz a soma de verificação para checar se o pacote não está corrompido e verifica também o número de sequência, para identificar se trata-se de um pacote novo ou uma retransmissão.
De acordo com o protocolo, conforme o servidor recebe os pacotes com os inteiros enviados pelo cliente, deve-se enviar mensagens de volta informando que o pacote foi recebido, e seu número de sequência do mesmo. O número de sequência permite a identificação de pacotes duplicados. Também é incluído um campo de soma de verificação, que permite identificar bits corrompidos no pacote. A estrutura das mensagens que são enviadas do servidor ao cliente é definida da seguinte forma:
- 16 bytes para porta de origem
- 16 bytes para porta de destino
- 16 bytes para comprimento total do pacote
- 1 byte para ACK
- 1 byte para número de sequência
- 16 bytes para soma de verificação
Dessa forma, a mensagem enviada pelo servidor possui um tamanho fixo de 66 bytes. O tamanho dos campos na mensagem foram expressos em bytes, mas na representação dos valores de cada campo, utilizam-se uma cadeia de bits de comprimento igual ao tamanho do campo em bytes. Isso se deu porque a representação é tratada na implementação como string, então mesmo que cada casa da representação só possa assumir os valor de 0 ou 1 (1 bit), o tamanho do tipo char é 1 byte. Esta representação foi utilizada por, mesmo ocupando mais espaço, ser de mais fácil manipulação.
O servidor mantém-se no estado nesse escuta, recebendo pacotes do cliente, e respondendo informações sobre o recebimento do pacote, com mensagens no formato descrito acima. O servidor se comporta conforme descreve o diagrama do destinatário da rdt 2.2. Além disso, o servidor mantém listas dos pacotes recebidos na ordem de envio, na ordem correta, pacotes duplicados e pacotes corrompidos.
5.2 – O CLIENTE
Assim como no servidor, no cliente são necessárias as etapas iniciais acima descritas de configuração de comunicação entre os processos, através da criação de sockets, definição de endereços e portas, etc. Primeiramente, a entrada de dados do programa é feito a partir de um arquivo. Este arquivo contém, em cada linha, um número inteiro que identifica cada pacote. O último pacote é identificado pelo inteiro -1. Foi feito um algoritmo básico “geraEntrada.py” que lê da entrada padrão o número de pacotes a serem gerados, e, a partir de um número
aleatório inicial entre 1 e 1000, escreve os pacotes no arquivo “entrada”.
Esses pacotes deverão ser enviados ao servidor pelo cliente, e, portanto, o arquivo de entrada deve ser lido pelo mesmo. O cliente mantém uma lista com os inteiros a serem enviados que devem ser embutidos nos dados de um pacote. A estrutura da mensagem que é enviada pelo cliente ao servidor é como segue:
- 16 bytes para porta de origem
- 16 bytes para porta de destino
- 16 bytes para comprimento total do pacote
- 16 bytes para soma de verificação
- 1 byte para número de sequência
- 32 bytes para o número inteiro (dado)
Dessa forma, a mensagem enviada pelo servidor possui um tamanho fixo de 97 bytes. Tendo-se a lista de pacotes que devem ser enviados, é apresentado ao usuáriouma interface que permite que ele: (1) – envie um pacote corretamente, (2) – envie um pacote com perda, (3) – envie um pacote duplicado, (4) – embaralhe a lista de pacotes atual, (5) – saia do programa. O próximo pacote a ser enviado é sempre o primeiro da lista, obtido pelo método push da lista.
Como ambos cliente e servidor estão executando em máquina local, o pacote não passa pelas interferências que se podem ocorrer em uma rede e que podem ocasionar problemas na entrega do pacote. Para isso, foi necessário simular essas perdas quando o usuário assim desejasse.
Para o envio com sucesso, o número de sequência, soma de verificação e demais campos da mensagem permanecem da forma como espera-se que estejam. Para simular o corrompimento dos dados, altera-se a soma de verificação enviada na mensagem, a fim de torná-la propositalmente incorreta. Dessa forma, quando o servidor realiza a soma de verificação dos campos e a compara com a soma enviada na mensagem, identifica-se bits corrompidos. Já para o caso de duplicar o pacote, deve-se alterar (também propositalmente) o número de sequência do pacote, para que este seja o mesmo do pacote enviado anteriormente. Assim, ao checar o número de sequência na mensagem, o servidor identificará o pacote como duplicado.
Mesmo se tratando de problemas induzidos, o servidor está programado segundo o protocolo rdt 2.2, e assim como em um problema real, deve-se recuperar dele. Assim, quando identifica um pacote corrompido ou duplicado, o mesmo envia uma mensagem ao cliente com informações do último pacote recebido (conforme descrito acima) e assim o cliente faz o reenvio, desta vez com o pacote sendo enviado com sucesso. Assim que o pacote é enviado, a interface é reapresentada ao cliente, com a lista de pacotes atualizada, e as mesmas opções citadas anteriormente. O programa segue até que o cliente entre com a opção de sair, ou não se tenha mais pacotes para enviar.
6 – CONCLUSÃO
Em geral, todas as máquinas na Internet podem ser classificadas como de dois tipos: servidores e clientes. As máquinas que fornecem serviços para outras máquinas são os servidores. As máquinas usadas para conectar esses serviços são os clientes. A implementação deste trabalho trouxe o entendimento do funcionamento desse modelo de um nível conceitual para um nível prático em que deve-se prever e tratar a ocorrência de problemas. Foi possível compreender melhor os fundamentos da transferência confiável de dados, que pode ser aplicada não somente à camada de transporte.
Por fim, podemos concluir que o trabalho foi de grande auxílio para praticar osconhecimentos adquiridos na disciplina de redes de computadores. Como trabalho complementar, pode sugerir-se a implementação do rdt 3.0, ou algum outro protocolo mais sofisticado que também forneça a entrega confiável de dados.
1 Comentário
Sannytet
12 de dezembro de 2018 at 04:45Nice posts! 🙂
___
Sanny