
A Web Crawler (also known as spider) is an algorithm that browses the web in order to collect data about a specific subject. That algorithm gather data from a source list (also called seeds), parsing the content to a well defined structure. An example of application would be to mine posts/news from a blog. In this post, I’m gonna show how to implement a script to collect posts for specific categories from the blog A Casa do Cogumelo (The Mushroom’s House – Super Mario Bros), but it can also be extended to any other blog developed with WordPress, once the HTML structure is pretty much the same.
There are some library options to make the data parsing on web pages easier. In Ruby, Nokogiri is usually the main choice of most developers. Another option would be Mechanize library, available not only in both Ruby and Python. To use Nokogiri, you should install the Ruby gem:
|
1 |
gem install nokogiri |
In the header of the code bellow, besides the libraries required, it’s also necessary to declare a set of addresses for the categories that will be explored by the crawler. Before implement or run the code, I encourage you to access those addresses and inspect page’s HTML to understand its structure and how the solution to retrieve the data was developed.
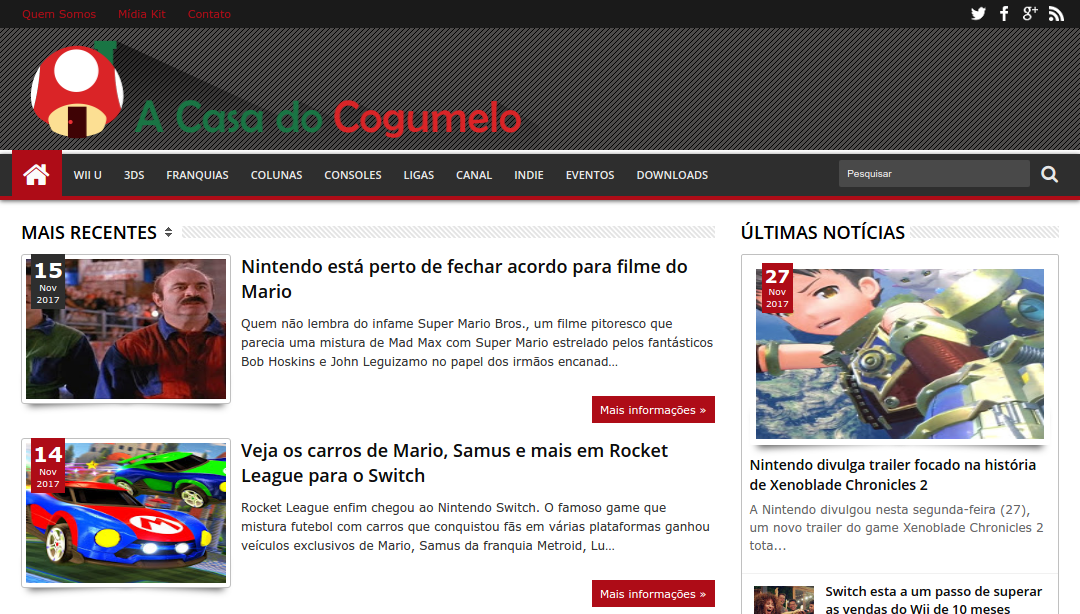
Category example – Super Mario
Inspecting section’s HTML where the post are listed, it was noticed that the DIV with the list always has the class “post-summary”. Inside that div, we can retrieve all links to the posts for that category. Those addresses must also be browsed, in order to retrieve the post content.
THE SOURCE CODE
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
#! /usr/bin/env ruby require 'nokogiri' require 'open-uri' categorias_urls = [ "http://www.acasadocogumelo.com/search/label/Mario", "http://www.acasadocogumelo.com/search/label/Pok%C3%A9mon", "http://www.acasadocogumelo.com/search/label/Donkey%20Kong", "http://www.acasadocogumelo.com/search/label/Zelda" ] categorias_urls.each do |url| # Fetch and parse HTML document doc = Nokogiri::HTML(open(url)) #Getting the post list for the category posts_summary = doc.css(".post-summary").search("strong").search("a").map{|a| [a.attributes["title"].value, a.attributes["href"].value]} #Parsing the content from each post posts_summary.each do |post| titulo_post = post[0] link_post = post[1] post = Nokogiri::HTML(open(link_post)) post_body = post.css(".post-body.entry-content").first.inner_html end end |
Once the blog in point was developed using WordPress, it makes so much easier to parse the post content. The most complex code line is the one that retrieve the posts links:
|
1 |
posts_summary = doc.css(".post-summary").search("strong").search("a").map{|a| [a.attributes["title"].value, a.attributes["href"].value]} |
In the document body, the algorithm searches for the class “post-summary”, which is the DIV containing the links. Those links, on other hand, are nested inside <STRONG> tags, so they’re browsed sequentially. In that set of links, it’s applied a map function, in order to obtain, for each post, its title and address. Once again, for those links, the algorithm does a new iteration to get the entire content for the post, which is inside the DIV with class “post-body entry-content”.
|
1 |
post_body = post.css(".post-body.entry-content").first.inner_html |
It’s worth to point out that, in this case, the content for the post has HTML tags, which should be striped if desired. Also, in an application that stores those posts in a database, it’s important to be careful and sanitize the content in order to avoid syntax errors caused by quotes, as well to prevent SQL code injection. If you have any doubts or suggestions, please use the comment area or contact me.
1 Comment
Sannytet
December 12th, 2018 at 03:54Nice posts! 🙂
___
Sanny